

Problem statement
Sometimes companies have complicated business logic that requires a custom scheduler or autoscaler in a Kubernetes cluster. The initial machine learning application design included 3 pods: web application (platform), pre-processing pod (preliminary data preparation), and processing pod with ML application. The main problem here was that the solution was NOT scalable and cost-effective. Processing is running on a GPU node and it is NOT always needed. So we decided to replace Kubernetes Pod with Job. The first idea was to use a message queue and KEDA (Kubernetes Event-driven Autoscaling), but we found out that there are a couple of nuances. The number of files for processing for every job and files size may vary greatly. We need to read and analyze a message from the queue and make a particular decision about the required processing algorithm. Moreover, we need to plan a future possibility of scheduling CPU jobs as well and parallel different processing algorithms for the same data. As a result, we decided that we need something custom.
Solution overview
The cost-effectiveness was improved by replacing Pods with Jobs and using Karpenter for nodes autoscaling. The speed of scaling was an issue, because files for processing in the S3 bucket may be up to 10 Gb, so it takes quite a long time to download and upload them several times within one processing workflow. That’s why we create one EBS as a persistent volume and then use it for different applications one by one.
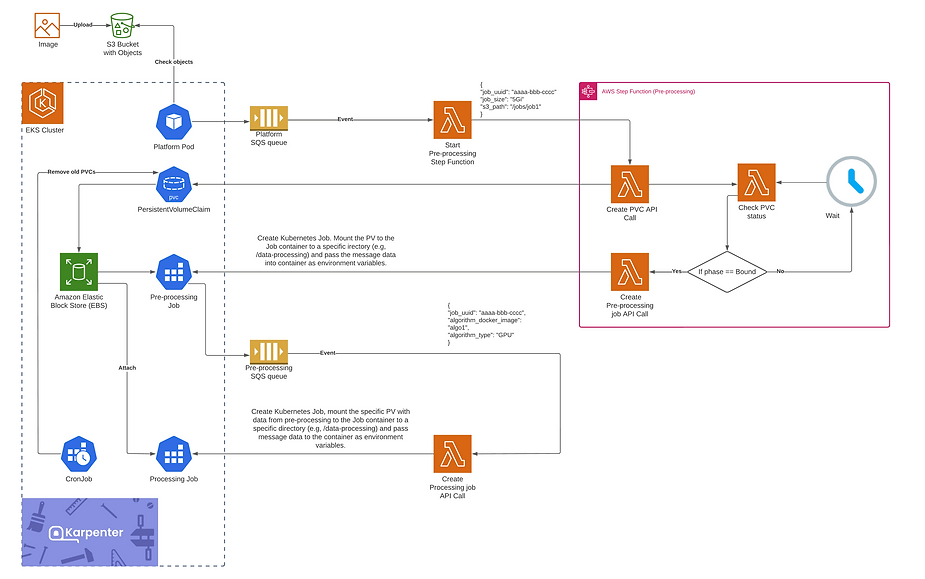
The workflow is as follows:
- End-user uploads files to S3 bucket.
- Platform application understands when all files required for processing are in S3 (there may be a different number of files and sizes). The platform creates a message in an SQS queue with a random Job ID, size of files, and path in S3.
- SQS event triggers a Lambda function that starts Step Function with an appropriate payload.
- Step Functions is used here because the workflow is asynchronous. The first step is creating a Persistent Volume Claim for the volume of a certain size in the defined availability zone. We can not use built-in Step Functions EKS integration, because it supports only Kubernetes APIs with public endpoint access. Our EKS cluster has only a private API endpoint according to the best practice, so we need Lambda functions that are deployed within VPC and can access the Private EKS API endpoint.
- Then a Lambda function continuously checks the status of the PVC
- Once PVC is bound, Lambda sends an API call to create a pre-processing job.
- Pre-processing Job starts with a mounted EBS volume, downloads files from S3, and performs preliminary data preparation for further processing. It also defines which algorithm should be used in the processing and sends this information into the SQS queue.
- Lambda function is executed with the required parameters (Job ID, algorithm type).
- The processing job starts with a mounted EBS volume that already contains pre-processed data.
- A separate Kubernetes cron-job is used for old volumes cleanup.
Example of the step function definition:
{
"Comment": "A description of my state machine",
"StartAt": "EKS Create PVC",
"States": {
"EKS Create PVC": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:eu-west-1:0**********3:function:eks-operations"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"ResultPath": "$.Result",
"Next": "GoToCheckPVC"
},
"GoToCheckPVC": {
"Type": "Pass",
"Result": "CheckPVC",
"ResultPath": "$.RequestType",
"Next": "EKS Check PVC"
},
"EKS Check PVC": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:eu-west-1:0**********3:function:eks-operations"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"ResultPath": "$.Result",
"Next": "StringToJsonForBody"
},
"StringToJsonForBody": {
"Type": "Pass",
"Next": "Choice",
"Parameters": {
"body.$": "States.StringToJson($.Result.Payload.body)"
},
"ResultPath": "$.Result.Payload"
},
"Choice": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.Result.Payload.body.status.phase",
"StringEquals": "Bound",
"Next": "GoToRunJob"
}
],
"Default": "Wait for PVC Creation"
},
"GoToRunJob": {
"Type": "Pass",
"Next": "EKS Run Pre-Processing Job",
"Result": "RunPreProcessingJob",
"ResultPath": "$.RequestType"
},
"EKS Run Pre-Processing Job": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:eu-west-1:0**********3:function:eks-operations"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"End": true
},
"Wait for PVC Creation": {
"Type": "Wait",
"Seconds": 15,
"Next": "GoToEKSCheckPVC"
},
"GoToEKSCheckPVC": {
"Type": "Pass",
"Result": "{}",
"ResultPath": "$.Result",
"Next": "EKS Check PVC"
}
}
}
Code of eks-operations Lambda that authenticates in EKS and makes API calls:
# lambda environment variables should be defined:
# EKS_CLUSTER_NAME - your cluster name
# REGION - cluster region
# NAMESPACE - job namespace
# MOUNT_PATH - PVC mount path
# PREPROCESSING_TAG - tag for preprocessing image
# PROCESSING_TAG - tag for processing image
import boto3
import base64
import json
import logging
import os
import tempfile
import yaml
from eks_token import get_token
from kubernetes import client, config
from kubernetes.client import configuration
from pprint import pprint
# Configure your cluster name and region here
KUBE_FILEPATH = '/tmp/kubeconfig'
CLUSTER_NAME = os.environ['EKS_CLUSTER_NAME']
REGION = os.environ['REGION']
NAMESPACE = os.environ['EKS_NAMESPACE']
MOUNT_PATH = os.environ['MOUNT_PATH']
PREPROCESSING_TAG = os.environ['PREPROCESSING_TAG']
PROCESSING_TAG = os.environ['PROCESSING_TAG']
def create_kube_config():
token = get_token(cluster_name=CLUSTER_NAME)['status']['token']
# Get data from EKS API
eks_api = boto3.client('eks',region_name=REGION)
cluster_info = eks_api.describe_cluster(name=CLUSTER_NAME)
certificate = cluster_info['cluster']['certificateAuthority']['data']
endpoint = cluster_info['cluster']['endpoint']
# Generating kubeconfig
kube_content = dict()
kube_content = {
'apiVersion': 'v1',
'clusters': [{
'cluster': {
'server': endpoint,
'certificate-authority-data': certificate
},
'name':'kubernetes'
}],
'contexts': [{
'context': {
'cluster':'kubernetes',
'user':'aws'
},
'name':'aws'
}],
'current-context': 'aws',
'Kind': 'config',
'users': [{
'name': 'aws',
'user': {'name': 'lambda', 'token': token}
}]
}
# Write kubeconfig
with open(KUBE_FILEPATH, 'w') as outfile:
yaml.dump(kube_content, outfile, default_flow_style=False)
def lambda_create_pvc(event,Api):
CoreV1Api = client.CoreV1Api(Api)
metadata = {'name': event['pvc']['name'], 'namespace': NAMESPACE}
requests = {'storage': event['pvc']['size']}
_V1ResourceRequirements=client.V1ResourceRequirements(requests=requests)
_V1PersistentVolumeClaimSpec=client.V1PersistentVolumeClaimSpec(resources=_V1ResourceRequirements,storage_class_name='ebs-gp2-1b',access_modes=['ReadWriteOnce'])
body = client.V1PersistentVolumeClaim(api_version='v1',kind='PersistentVolumeClaim', metadata=metadata,spec=_V1PersistentVolumeClaimSpec,)
api_response = CoreV1Api.create_namespaced_persistent_volume_claim('default', body)
return json.dumps({"status": { "name": event['pvc']['name'], "phase": api_response.status.phase}})
def lambda_status_pvc(event,Api):
CoreV1Api = client.CoreV1Api(Api)
name = event['pvc']['name'] # str | name of the PersistentVolumeClaim
namespace = NAMESPACE
api_response = CoreV1Api.read_namespaced_persistent_volume_claim_status(name, namespace)
return json.dumps({'status': { 'name': event['pvc']['name'], 'phase': api_response.status.phase}})
def lambda_create_preprocessing_job(event,Api):
BatchV1Api = client.BatchV1Api(Api)
# Configureate Pod template container
container = client.V1Container(
name = f"job-pre-processing-{event['pvc']['name']}",
image = f"0**********3.dkr.ecr.eu-west-1.amazonaws.com/preprocessing:{PREPROCESSING_TAG}",
image_pull_policy = "IfNotPresent",
volume_mounts = [
client.V1VolumeMount(name="pvc-storage",mount_path='/mnt')
],
env = [
client.V1EnvVar(name="ACC_NUM", value=f"{event['s3']['path']}"),
client.V1EnvVar(name="JOB_UUID", value=event['pvc']['name']),
client.V1EnvVar(name="MOUNT_PATH", value=MOUNT_PATH)
],
env_from = [
client.V1EnvFromSource(secret_ref=client.V1SecretEnvSource(name="sqs-platform-env")),
client.V1EnvFromSource(secret_ref=client.V1SecretEnvSource(name="sqs-platform-rds-specific-creds"))
],
resources = client.V1ResourceRequirements(
requests={"cpu": "6", "memory": "24Gi"},
limits={"cpu": "7", "memory": "26Gi"}
)
)
volume = client.V1Volume(
name="pvc-storage",
persistent_volume_claim=client.V1PersistentVolumeClaimVolumeSource(claim_name=event['pvc']['name'])
)
nodeselector = {'load_type': 'gpu'}
toleration = [client.V1Toleration(key="karpenter", operator="Equal", effect="NoSchedule")]
# Create and configure a spec section
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(name=f"job-pre-processing-{event['pvc']['name']}", namespace=NAMESPACE, labels={"job": event['pvc']['name']}),
# spec=client.V1PodSpec(restart_policy="Never", volumes=[volume], containers=[container]))
spec=client.V1PodSpec(restart_policy="Never", node_selector=nodeselector, volumes=[volume], tolerations=toleration, containers=[container]))
# Create the specification of deployment
spec = client.V1JobSpec(
template=template,
ttl_seconds_after_finished=300,
backoff_limit=4)
# Instantiate the job object
job = client.V1Job(
api_version="batch/v1",
kind="Job",
metadata=client.V1ObjectMeta(name=f"job-pre-processing-{event['pvc']['name']}"),
spec=spec)
api_response = BatchV1Api.create_namespaced_job(
body=job,
namespace=NAMESPACE)
print(f"Job created. status={str(api_response.status)}")
return json.dumps({'status': { 'name': event['pvc']['name'], 'kind': api_response.kind, 'metadata': api_response.metadata.name }})
def lambda_create_processing_job(event,Api):
BatchV1Api = client.BatchV1Api(Api)
# Configureate Pod template container
container = client.V1Container(
name=f"job-processing-{event['job_uuid']}",
image=event['algorithm_docker_image'],
image_pull_policy="IfNotPresent",
volume_mounts=[client.V1VolumeMount(name="pvc-storage",mount_path='/mnt')],
env=[client.V1EnvVar(name="ALGORITHM_TYPE", value=event['algorithm_type']),
client.V1EnvVar(name="JOB_UUID", value=event['job_uuid']),
client.V1EnvVar(name="MOUNT_PATH", value=MOUNT_PATH)]
)
volume = client.V1Volume(
name="pvc-storage",
persistent_volume_claim=client.V1PersistentVolumeClaimVolumeSource(claim_name=event['job_uuid'])
)
# Create and configure a spec section
template = client.V1PodTemplateSpec(
metadata=client.V1ObjectMeta(name=f"job-processing-{event['job_uuid']}", namespace=NAMESPACE, labels={"job": event['job_uuid']}),
spec=client.V1PodSpec(restart_policy="Never", volumes=[volume], containers=[container]))
# Create the specification of deployment
spec = client.V1JobSpec(
template=template,
ttl_seconds_after_finished=300,
backoff_limit=4)
# Instantiate the job object
job = client.V1Job(
api_version="batch/v1",
kind="Job",
metadata=client.V1ObjectMeta(name=f"job-processing-{event['job_uuid']}"),
spec=spec)
api_response = BatchV1Api.create_namespaced_job(
body=job,
namespace=NAMESPACE)
print(f"Job created. status={str(api_response.status)}")
return json.dumps({'status': { 'name': event['pvc']['name'], 'kind': api_response.kind, 'metadata': api_response.metadata.name }})
def lambda_list_all_pvc(event,Api):
CoreV1Api = client.CoreV1Api(Api)
print("---- PVCs ---")
ret = CoreV1Api.list_persistent_volume_claim_for_all_namespaces(watch=False)
print(f"{'Name':{16}}\t{'Volume':{40}}\t{'Size':{6}}")
for i in ret.items:
print(f"{i.metadata.name:{16}}\t{i.spec.volume_name:{40}}\t{i.spec.resources.requests['storage']:{6}}")
return json.dumps({'status': 'ok'})
def lambda_handler(event, context):
# Configure
create_kube_config()
config.load_kube_config(KUBE_FILEPATH)
configuration = client.Configuration().get_default_copy()
api = client.ApiClient(configuration)
if event['RequestType'] == 'Create':
result = lambda_create_pvc(event,api)
elif event['RequestType'] == 'Check':
result = lambda_status_pvc(event,api)
elif event['RequestType'] == 'RunPreProcessingJob':
result = lambda_create_preprocessing_job(event,api)
elif event['RequestType'] == 'RunProcessingJob':
result = lambda_create_processing_job(event,api)
elif event['RequestType'] == 'Test':
result = lambda_list_all_pvc(event,api)
return {
'statusCode': 200,
'body': result
}
Conclusion
In this post, I described how we solved several problems for the machine learning application in Kubernetes: running GPU nodes only when they are required, horizontally scaling the application by scheduling parallel jobs, increasing the processing speed by using the same EBS persistent volume, and reattaching it to subsequent Job containers. The solution is secure because we keep using the Private API endpoint despite the limitation of the standard Step Function for calling EKS API. Besides the solution is extensible for new features that our customer is planning to implement.
