

Machine Learning is everywhere. Even if not everywhere, the majority of people face it every day while surfing the internet, buying things online, watching videos, listening to music and many other activities. Machine learning is integrated in social media, ecommerce, healthcare, banking, manufacturing and other industries. It helps to enhance the customer service experience, personalize customer recommendations, automate data extraction and analysis, maximize the value of media, improve business metrics analysis, identify fraudulent online activities, etc. Possibilities are endless.
AWS is working hard in this direction and if you open a list of ML services, you will see the following:
| Amazon SageMaker | Amazon Augmented AI |
| Amazon CodeGuru | Amazon DevOps Guru |
| Amazon Comprehend | Amazon Forecast |
| Amazon Fraud Detector | Amazon Kendra |
| Amazon Lex | Amazon Personalize |
| Amazon Polly | Amazon Rekognition |
| Amazon Textract | Amazon Transcribe |
| Amazon Translate | AWS DeepComposer |
| AWS DeepLens | AWS DeepRacer |
| AWS Panorama | Amazon Monitron |
| Amazon HealthLake | Amazon Lookout for Vision |
| Amazon Lookout for Equipment | Amazon Lookout for Metrics |
There will be a series of posts about these services. In this post we will take a look at Amazon SageMaker and Amazon Rekognition.
Amazon SageMaker
Amazon Sagemaker is a king of ML services in AWS. More specifically it is not a single service, it’s rather a family of services and it should be discussed in a separate post. Here we will just look at Amazon Sagemaker in general.
Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning models quickly by bringing together a broad set of capabilities purpose-built for machine learning.
In general a workflow is following:
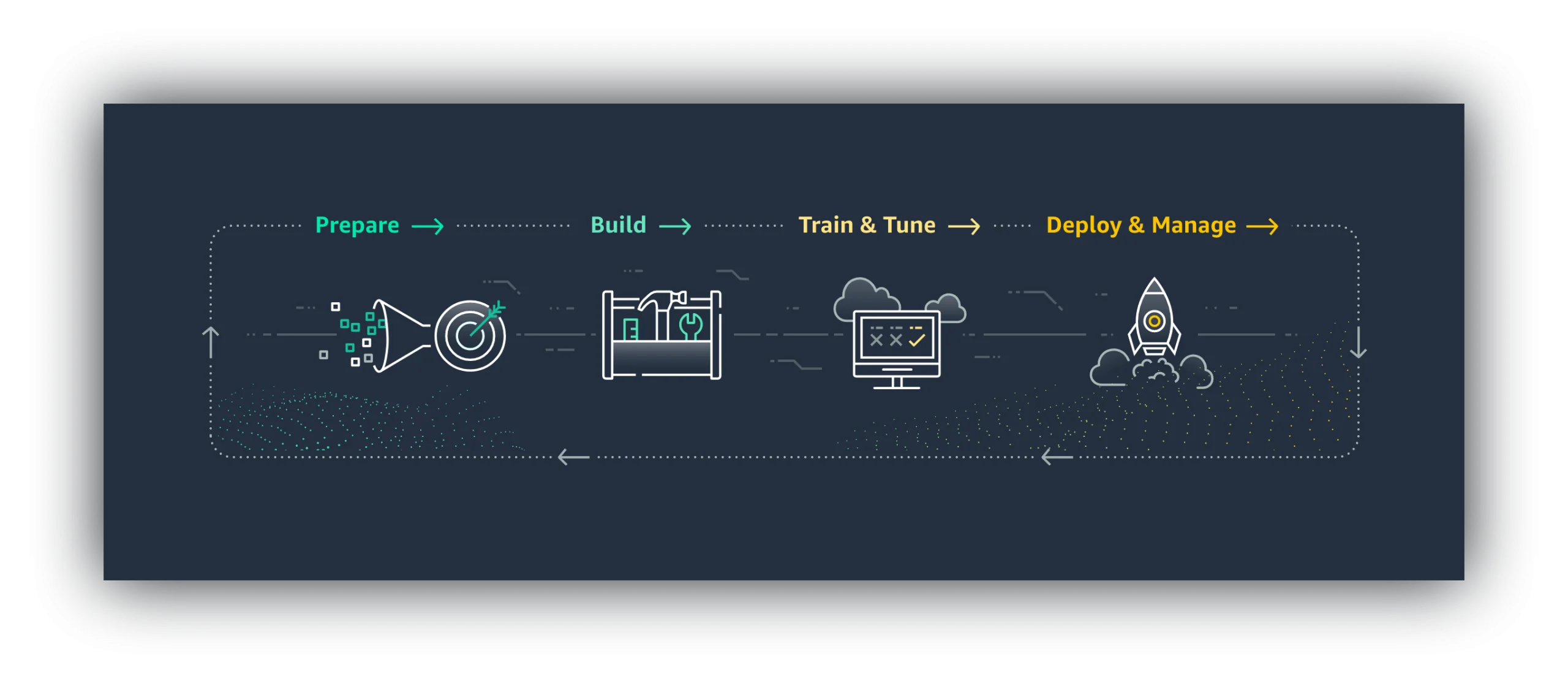
- Understand what a model has to predict and prepare data for machine learning (choose right features, aggregate, deal with missing values, etc.)
- Use a built-in algorithm, develop your own or try to find one in the Marketplace.
- Allocate needed resources and train a model. Compare different algorithms, tune hyperparameters and debug.
- Deploy a model, create an endpoint, make predictions and monitor a process.
The high-level view is following:
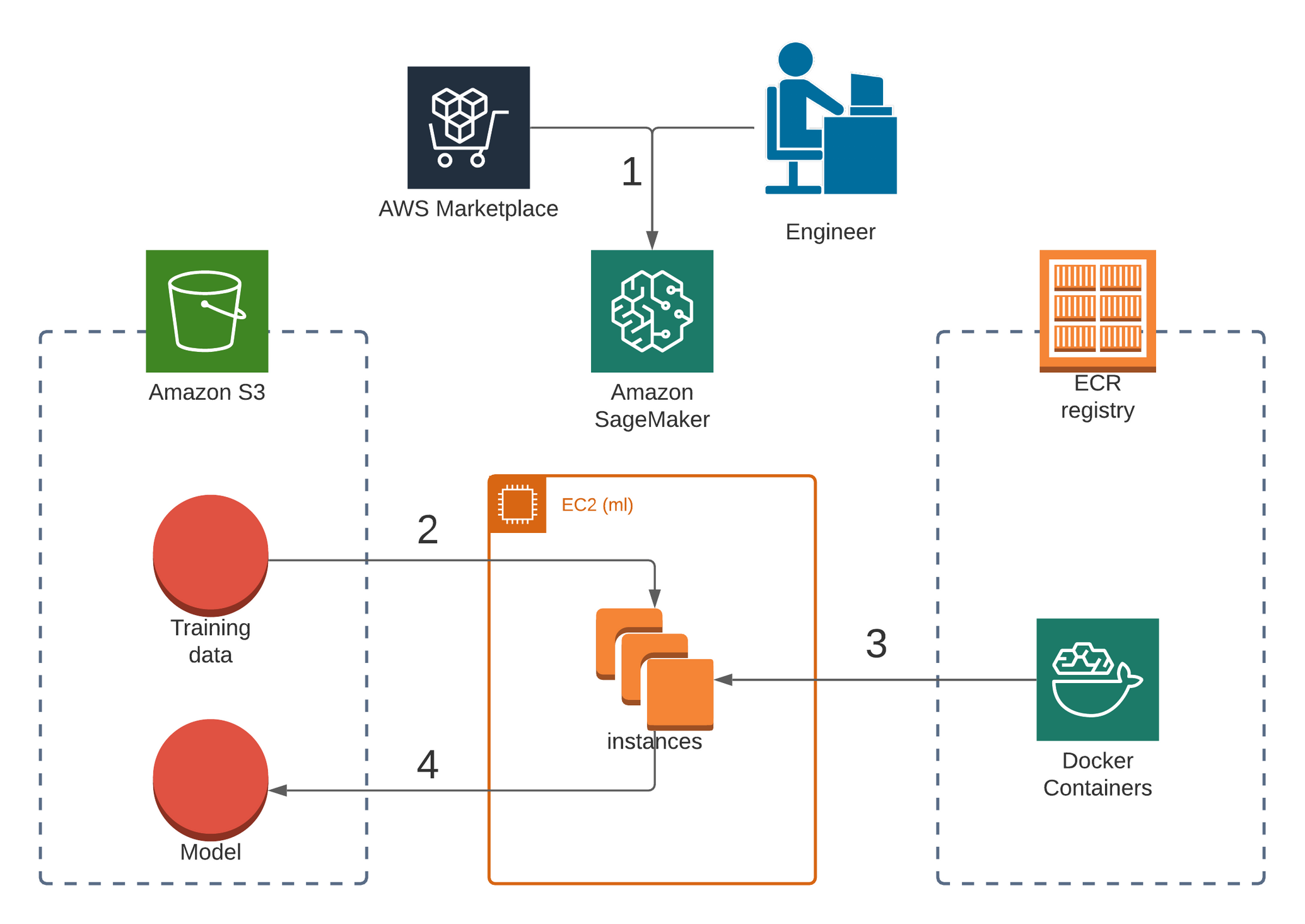
- First of all you need to understand the purpose of using machine learning in your case and choose an algorithm. There are 17 built-in algorithms in Sagemaker, applicable in different situations and circumstances. You can also check AWS Marketplace or develop your own algorithm.
- Then you need to prepare training and testing data sets (optionally validation dataset as well) and upload it to S3 bucket.
- After that you need to build your model. Choose the appropriate type of EC2 instance. An algorithm container will be pulled there and later used for training a model.
- Start a training job and wait till completion. A model will be uploaded to S3 bucket.
A map of use cases and suitable algorithms is below:
| Example problems and use cases | Built-in algorithms |
|---|---|
| Predict if an item belongs to a category: an email spam filter | Factorization Machines Algorithm, K-Nearest Neighbors (k-NN) Algorithm, Linear Learner Algorithm, XGBoost Algorithm |
| Predict a numeric/continuous value: estimate the value of a house | Factorization Machines Algorithm, K-Nearest Neighbors (k-NN) Algorithm, Linear Learner Algorithm, XGBoost Algorithm |
| Based on historical data for a behavior, predict future behavior: predict sales on a new product based on previous sales data. | DeepAR Forecasting Algorithm |
| Improve the data embeddings of the high-dimensional objects: identify duplicate support tickets or find the correct routing based on similarity of text in the tickets | Object2Vec Algorithm |
| Drop those columns from a dataset that have a weak relation with the label/target variable: the color of a car when predicting its mileage. | Principal Component Analysis (PCA) Algorithm |
| Detect abnormal behavior in application: spot when an IoT sensor is sending abnormal readings | Random Cut Forest (RCF) Algorithm |
| Protect your application from suspicious users: detect if an IP address accessing a service might be from a bad actor | IP Insights |
| Group similar objects/data together: find high-, medium-, and low-spending customers from their transaction histories | K-Means Algorithm |
| Organize a set of documents into topics (not known in advance): tag a document as belonging to a medical category based on the terms used in the document. | Latent Dirichlet Allocation (LDA) Algorithm, Neural Topic Model (NTM) Algorithm |
| Assign predefined categories to documents in a corpus: categorize books in a library into academic disciplines | BlazingText algorithm |
| Convert text from one language to other: Spanish to English | Sequence-to-Sequence Algorithm |
| Summarize a long text corpus: an abstract for a research paper | Sequence-to-Sequence Algorithm |
| Convert audio files to text: transcribe call center conversations for further analysis | Sequence-to-Sequence Algorithm |
| Label/tag an image based on the content of the image: alerts about adult content in an image | Image Classification Algorithm |
| Detect people and objects in an image: police review a large photo gallery for a missing person | Object Detection Algorithm |
| Tag every pixel of an image individually with a category: self-driving cars prepare to identify objects in their way | Semantic Segmentation Algorithm |
If a model efficiency is unsatisfactory, you can try to tune hyperparameters or maybe you have chosen a wrong algorithm and you should try another one. After that, train a model again. When your model is ready, you can deploy and use it.
Jupyter Notebook
One more interesting feature of Amazon SageMaker is Jupyter notebooks. It is a virtual environment with kind of IDE, where you can interactively create a model using TensorFlow, PyTorch or other frameworks, download, explore, and transform data, train a model, deploy and evaluate it.
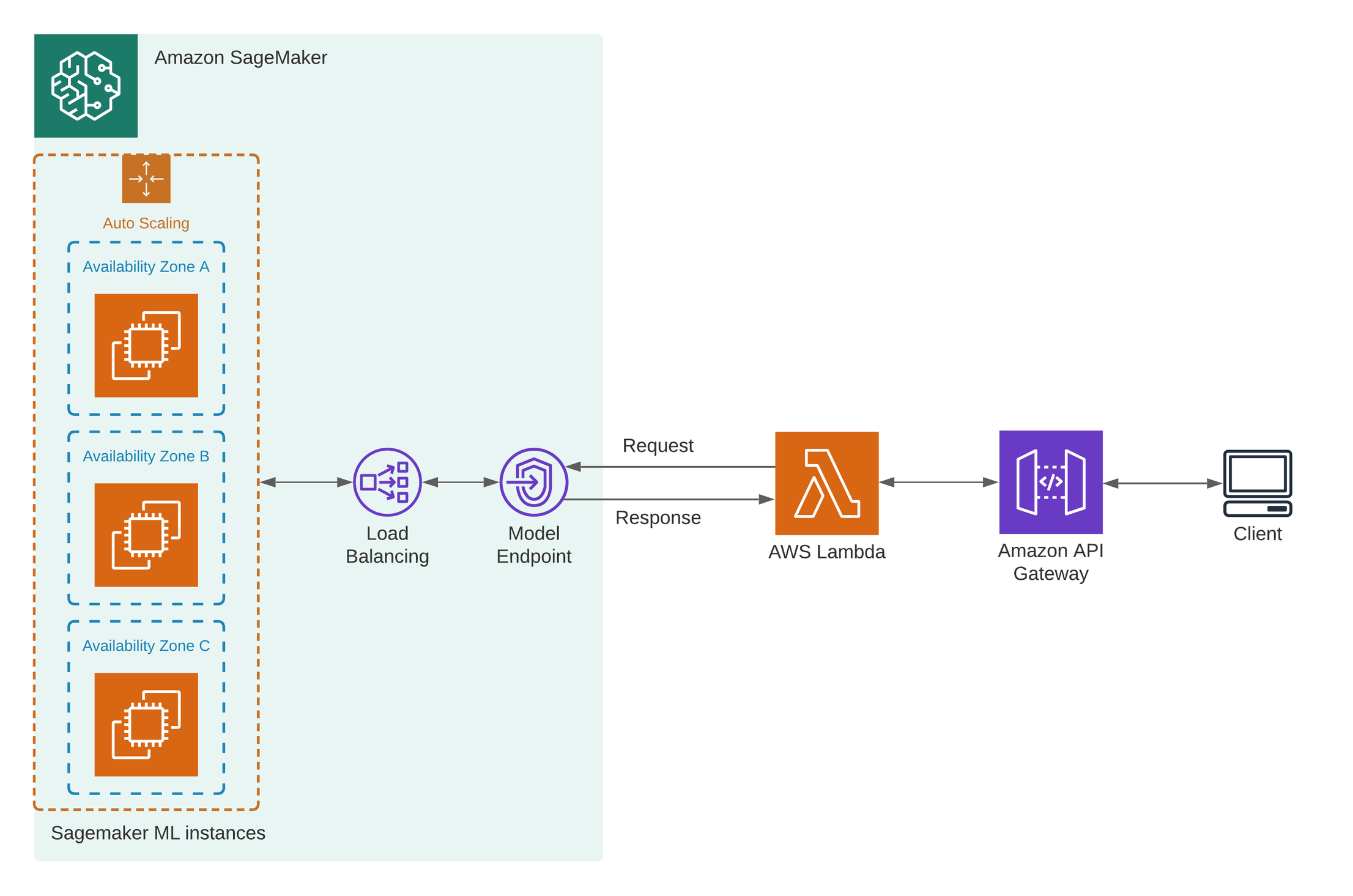
SageMaker endpoint
When ML model is trained, we can deploy and use it. We can add more ML instances in different availability zones. They will be exposed by Model Endpoint and you can send API calls directly to SageMaker endpoint or via Lambda and API Gateway.
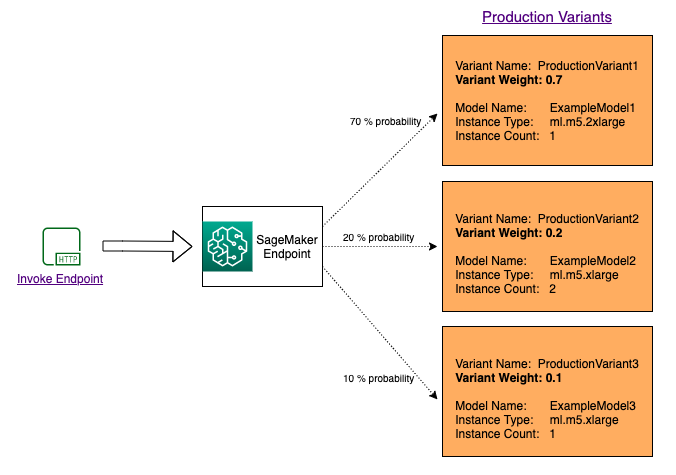
SageMaker A/B testing
You can disctribute traffic among diffetent models in order to perform A/B testing and minimize a risk of failure of new model. Variants can use different model, instance types and number of instances.
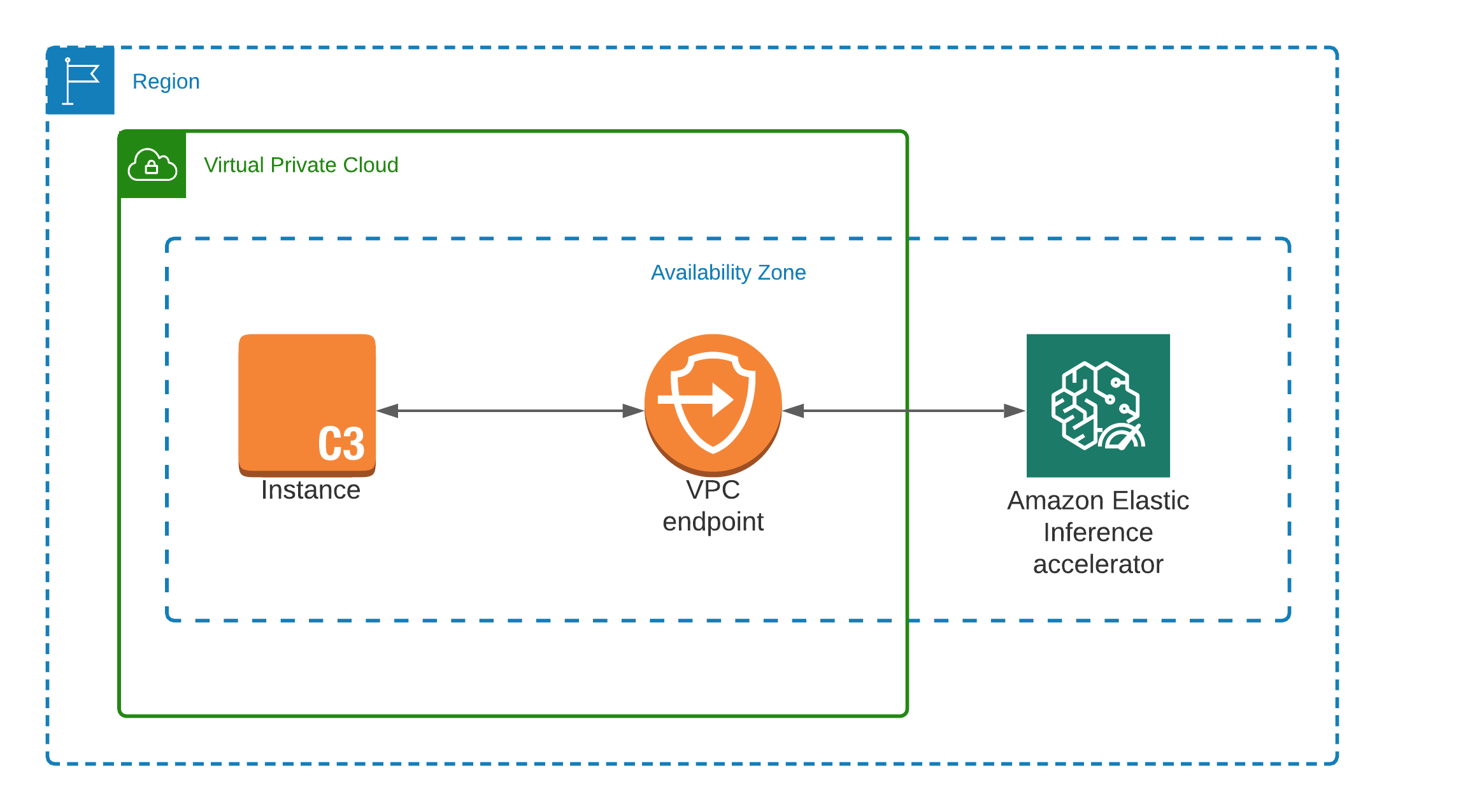
Amazon Elastic Inference
If you need to accelerate an inference process, check Elastic Inference out. Amazon Elastic Inference accelerators are network attached devices that work along with SageMaker instances in your endpoint to accelerate your inference calls. Elastic Inference accelerates inference by allowing you to attach fractional GPUs to any SageMaker instance. You can select the client instance to run your application and attach an Elastic Inference accelerator to use the right amount of GPU acceleration for your inference needs. Elastic Inference helps you lower your cost when not fully utilizing your GPU instance for inference.
A real example of building and training a ML model is quite an advanced topic and not the purpose of this post. Next we will check several AWS services that are based on Machine and Deep learning, but don’t require any knowledge in data and computer science.
Amazon Rekognition
Amazon Rekognition makes it easy to add image or video analysis to your applications using proven, highly scalable, deep learning technology that requires no machine learning expertise to use. It can be used for:
- Content moderation by detecting potentially unsafe, inappropriate, or unwanted content across images and videos.
- Face comparing and search by determining the similarity of a face against another picture or from your private image repository.
- Face detection and analysis in images and videos and recognizing attributes such as open eyes, glasses, and facial hair for each.
- Detecting objects and scenes and labeling them.
- Detecting custom objects such as brand logos (after training your models with as few as 10 images).
- Text detection by extracting skewed and distorted text from images and videos of street signs, social media posts, and product packaging.
- Celebrity recognition by identifying well-known people to catalog photos and footage for media, marketing, and advertising.
- Detection of key segments in videos, such as black frames, start or end credits, slates, color bars, and shots.
- Detection of Personal Protective Equipment (PPE) such as helmets, gloves, and masks on persons in images.
Below is an example of how object detection and labeling works:
A request contains an image location:
{
"Image": {
"S3Object": {
"Bucket": "rekognition-console-sample-images-prod-iad",
"Name": "skateboard.jpg"
}
}
}
Amazon Rekognition detects many objects with some confidence level
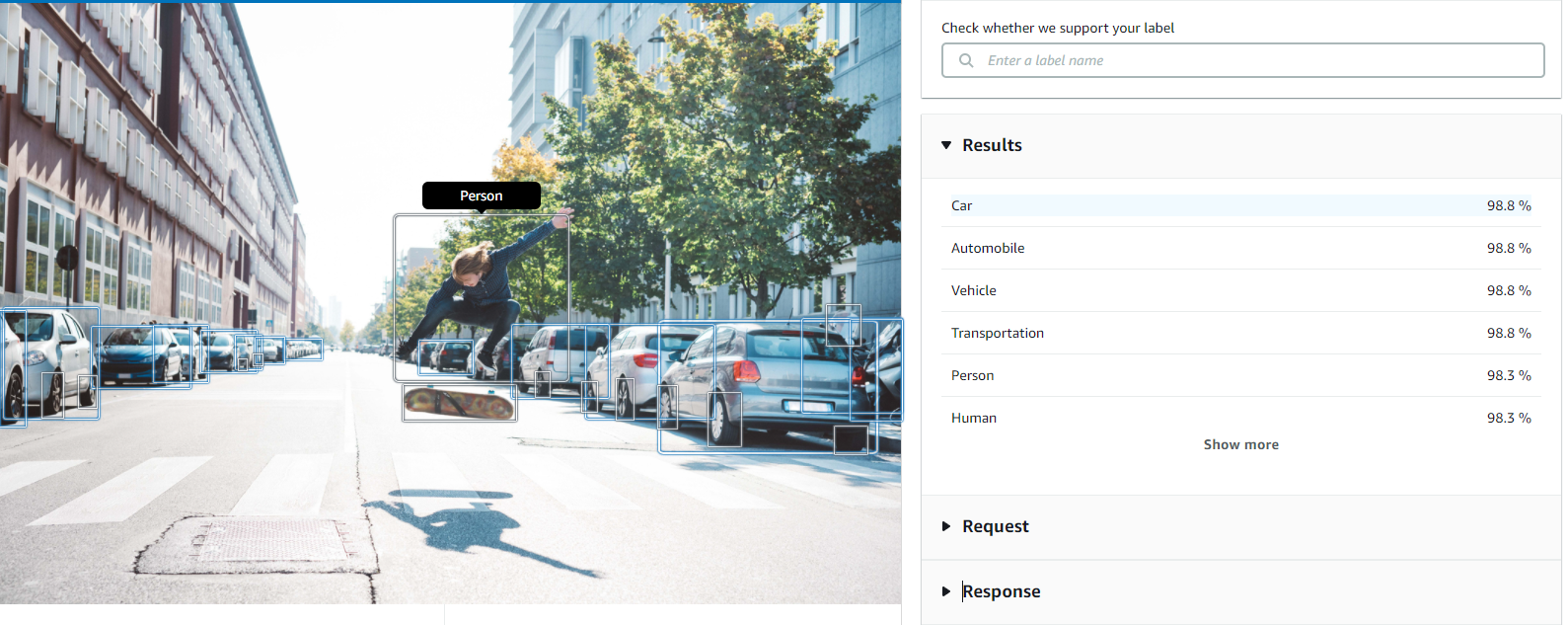
| Car 98.8 % | Automobile 98.8 % | Vehicle 98.8 % |
| Transportation 98.8 % | Person 98.3 % | Human 98.3 % |
| Pedestrian 97.1 % | Skateboard 94.3 % | Sport 94.3 % |
| Sports 94.3 % | Road 92.4 % | Wheel 90.8 % |
| Machine 90.8 % | Path 90.7 % | Downtown 89.8 % |
| City 89.8 % | Urban 89.8 % | Building 89.8 % |
| Town 89.8 % | Tarmac 86.1 % | Asphalt 86.1 % |
| Parking Lot 85.4 % | Parking 85.4 % | Intersection 84.8 % |
| Architecture 80.8 % | Office Building 62.9 % | Sidewalk 62.8 % |
| Pavement 62.8 % | Neighborhood 59.8 % | Street 56.9 % |
| Coupe 56 % | Sports Car 56 % | Sedan 55.4 % |
A response will be in a format:
{
"Labels": [
{
"Name": "Car",
"Confidence": 98.87621307373047,
"Instances": [
{
"BoundingBox": {
"Width": 0.10527367144823074,
"Height": 0.18472492694854736,
"Left": 0.0042892382480204105,
"Top": 0.5051581859588623
},
"Confidence": 98.87621307373047
},
… and so on
{
"Name": "Sedan",
"Confidence": 55.48483657836914,
"Instances": [],
"Parents": [
{
"Name": "Car"
},
{
"Name": "Vehicle"
},
{
"Name": "Transportation"
}
]
}
],
"LabelModelVersion": "2.0"
}
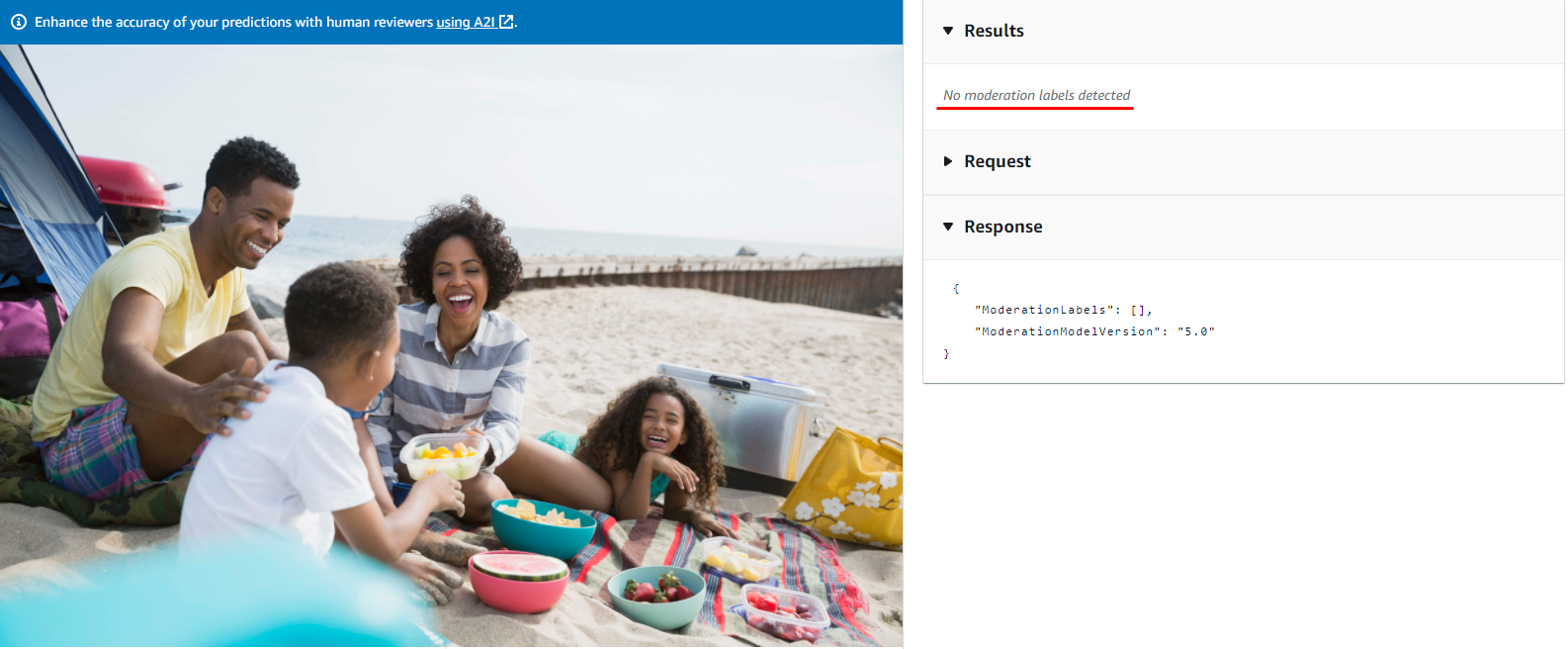
Another example:
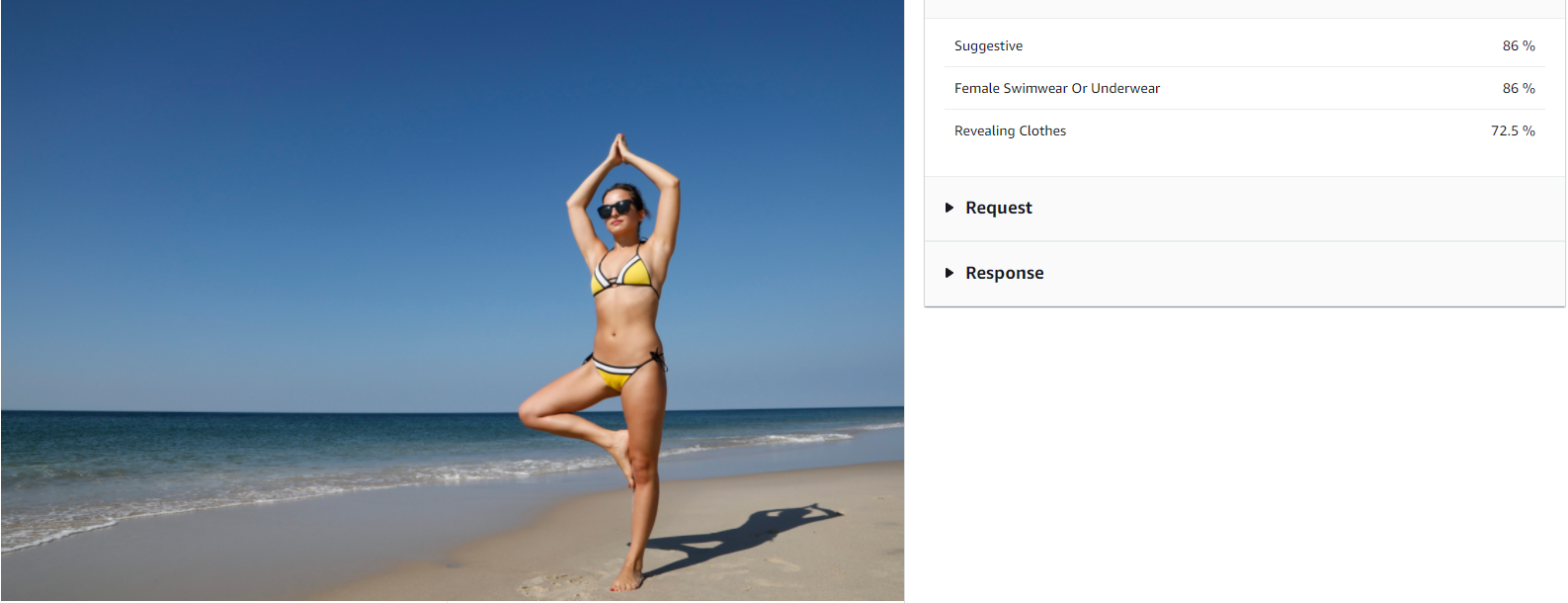
A response format:
{
"ModerationLabels": [
{
"Confidence": 86.06100463867188,
"Name": "Suggestive",
"ParentName": ""
},
{
"Confidence": 86.06100463867188,
"Name": "Female Swimwear Or Underwear",
"ParentName": "Suggestive"
},
{
"Confidence": 72.55979919433594,
"Name": "Revealing Clothes",
"ParentName": "Suggestive"
}
],
"ModerationModelVersion": "5.0"
}
Facial analysis provides us with details about all detected people:
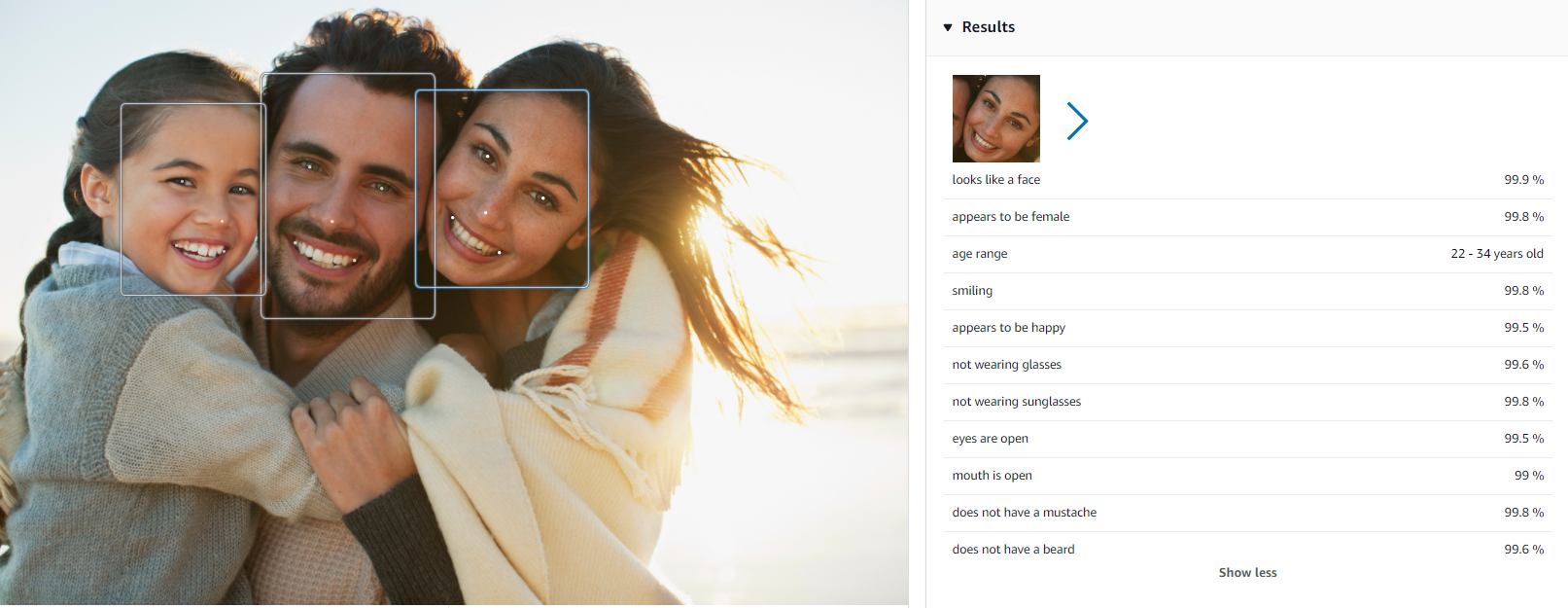
Example of a response:
{
"FaceDetails": [
{
"BoundingBox": {
"Width": 0.18937082588672638,
"Height": 0.4006582796573639,
"Left": 0.2870060205459595,
"Top": 0.12157715111970901
},
"AgeRange": {
"Low": 22,
"High": 34
},
"Smile": {
"Value": true,
"Confidence": 99.95774841308594
},
...
"Landmarks": [
{
"Type": "eyeLeft",
"X": 0.34175100922584534,
"Y": 0.2763494849205017
},
{
"Type": "eyeRight",
"X": 0.42029869556427,
"Y": 0.3119548559188843
},
...
How Amazon Rekognition can recognize celebrities:
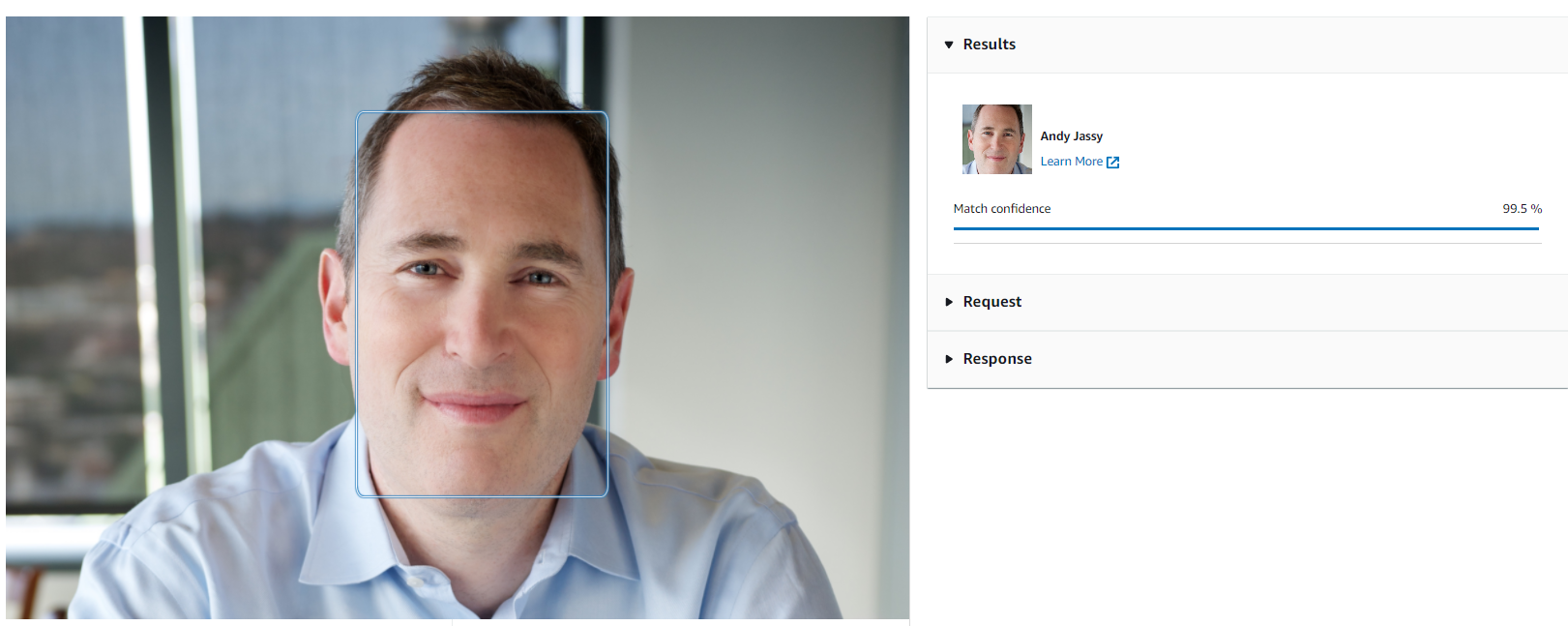
Example of response:
{
"CelebrityFaces": [
{
"Urls": [
"www.wikidata.org/wiki/Q41812531"
],
"Name": "Andy Jassy",
"Id": "3a3b6a",
"Face": {
"BoundingBox": {
"Width": 0.2764742076396942,
"Height": 0.6351656913757324,
"Left": 0.38734355568885803,
"Top": 0.1567412167787552
},
"Confidence": 99.99234771728516,
"Landmarks": [
{
"Type": "mouthRight",
"X": 0.5722469687461853,
"Y": 0.6434628367424011
},
{
"Type": "mouthLeft",
"X": 0.46705326437950134,
"Y": 0.6325944066047668
},
{
"Type": "nose",
"X": 0.52621990442276,
"Y": 0.539512574672699
},
{
"Type": "eyeRight",
"X": 0.5916759371757507,
"Y": 0.4337158799171448
},
{
"Type": "eyeLeft",
"X": 0.4652356803417206,
"Y": 0.4204119145870209
}
],
"Pose": {
"Roll": 3.141669273376465,
"Yaw": 1.072690486907959,
"Pitch": 3.4402129650115967
},
"Quality": {
"Brightness": 90.61405944824219,
"Sharpness": 86.86019134521484
},
"Emotions": [
{
"Type": "HAPPY",
"Confidence": 95.57534790039062
},
{
"Type": "CALM",
"Confidence": 3.899872303009033
},
{
"Type": "CONFUSED",
"Confidence": 0.21543452143669128
},
{
"Type": "SURPRISED",
"Confidence": 0.1186400055885315
},
{
"Type": "ANGRY",
"Confidence": 0.06282564997673035
},
{
"Type": "DISGUSTED",
"Confidence": 0.062092848122119904
},
{
"Type": "SAD",
"Confidence": 0.039690468460321426
},
{
"Type": "FEAR",
"Confidence": 0.026104968041181564
}
],
"Smile": {
"Value": true,
"Confidence": 81.47467041015625
}
},
"MatchConfidence": 99.55595397949219,
"KnownGender": {
"Type": "Male"
}
}
],
"UnrecognizedFaces": []
}
Andy seems happy.
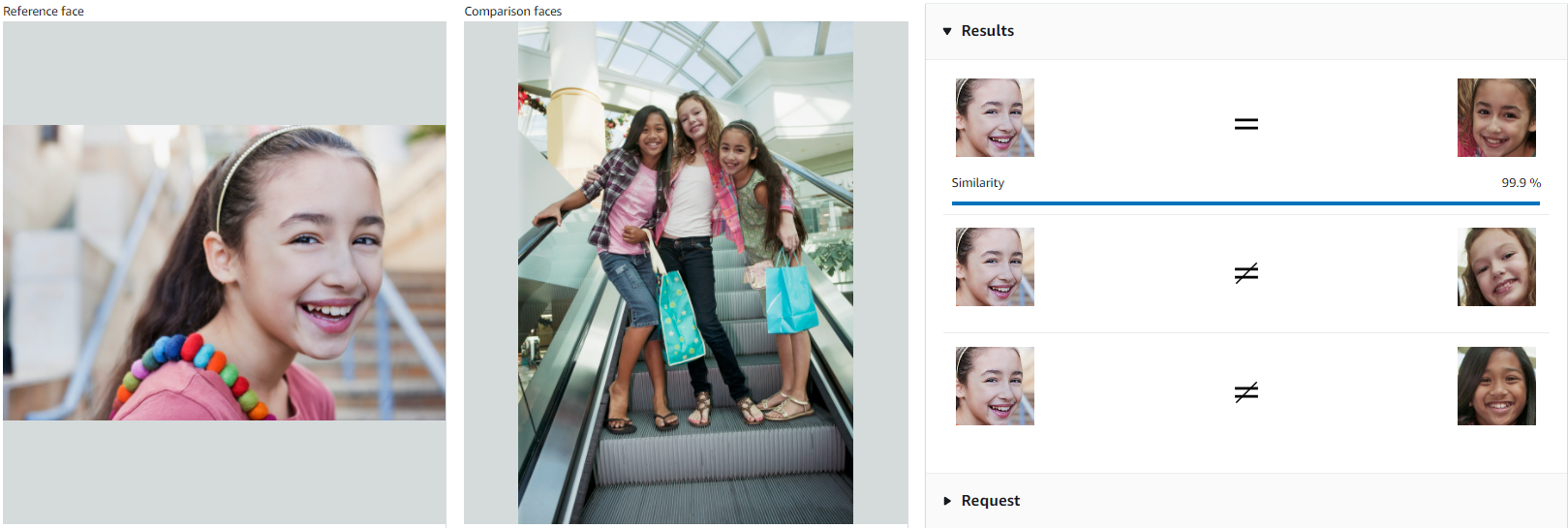
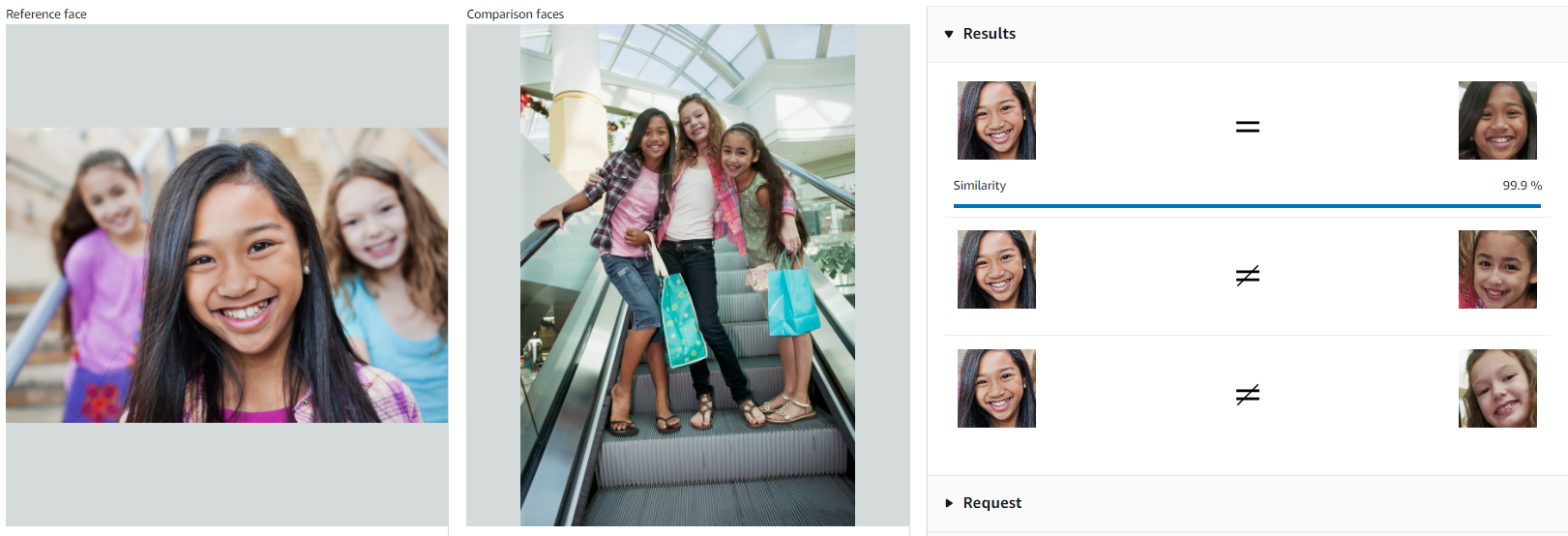
A Face comparison feature allows us to find a particular person on the image:
How text recognition and extraction works:

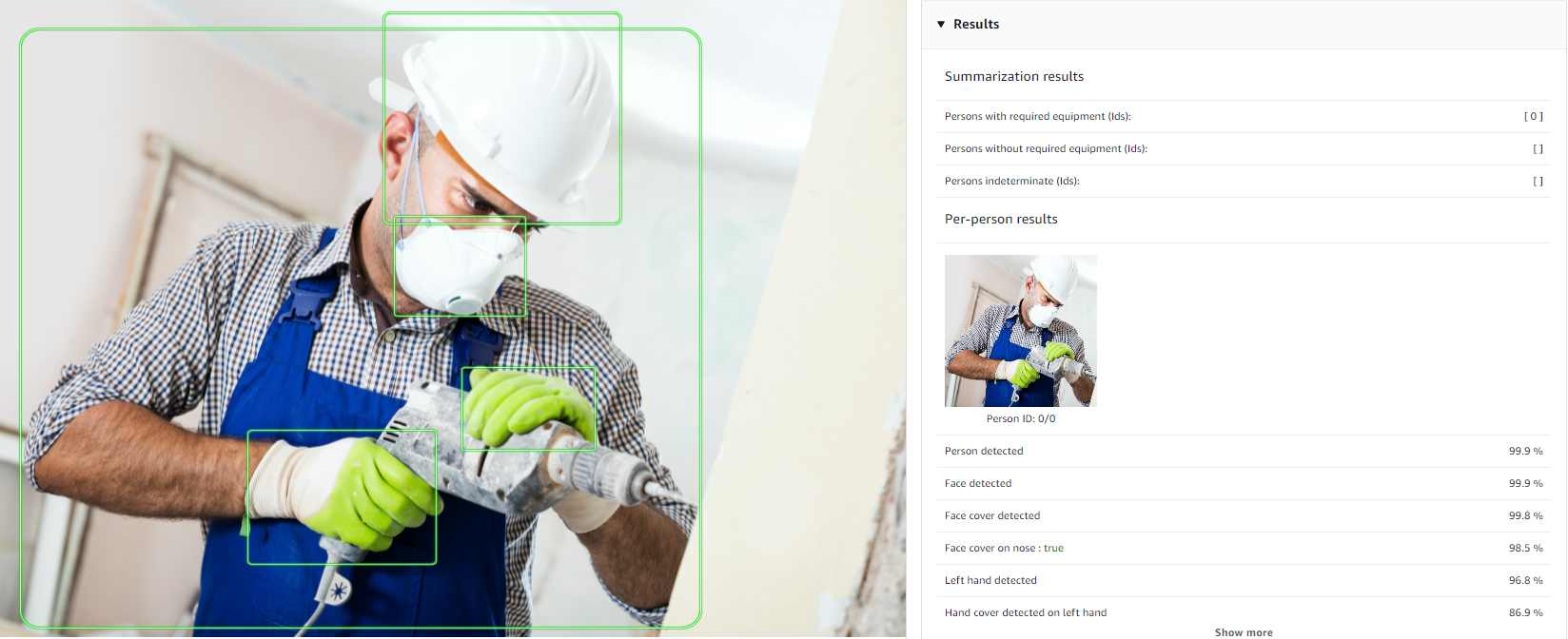
How Personal Protective Equipment (PPE) detection works:
We can make some part of equipment mandatory or not by following request:
{
"Image": {
"S3Object": {
"Bucket": "rekognition-console-sample-images-prod-iad",
"Name": "ppe_group_updated.jpg"
}
},
"SummarizationAttributes": {
"MinConfidence": 80,
"RequiredEquipmentTypes": [
"FACE_COVER",
"HAND_COVER",
"HEAD_COVER"
]
}
}
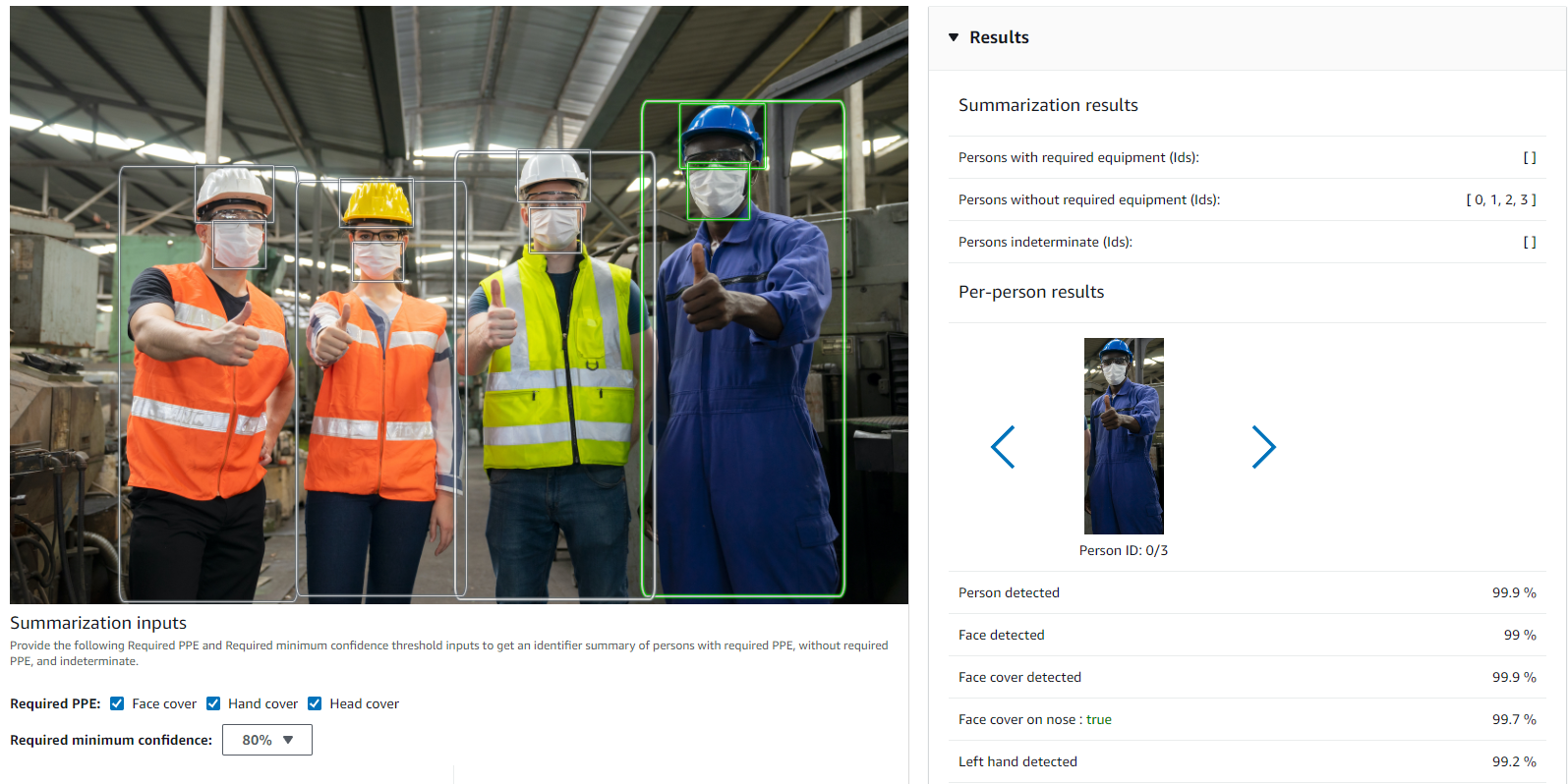
People depicted here are without gloves, but we required it above:
{
"ProtectiveEquipmentModelVersion": "1.0",
"Persons": [
{
"BodyParts": [
{
"Name": "FACE",
"Confidence": 99.07738494873047,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.06805413216352463,
"Height": 0.09381836652755737,
"Left": 0.7537466287612915,
"Top": 0.26088595390319824
},
"Confidence": 99.98419189453125,
"Type": "FACE_COVER",
"CoversBodyPart": {
"Confidence": 99.76295471191406,
"Value": true
}
}
]
},
{
"Name": "LEFT_HAND",
"Confidence": 99.25702667236328,
"EquipmentDetections": []
},
{
"Name": "RIGHT_HAND",
"Confidence": 80.11490631103516,
"EquipmentDetections": []
},
{
"Name": "HEAD",
"Confidence": 99.9693374633789,
"EquipmentDetections": [
{
"BoundingBox": {
"Width": 0.09358207136392593,
"Height": 0.10753925144672394,
"Left": 0.7455776929855347,
"Top": 0.16204142570495605
},
"Confidence": 98.4826889038086,
"Type": "HEAD_COVER",
"CoversBodyPart": {
"Confidence": 99.99744415283203,
"Value": true
}
}
]
}
],
...
"Summary": {
"PersonsWithRequiredEquipment": [],
"PersonsWithoutRequiredEquipment": [
0,
1,
2,
3
],
"PersonsIndeterminate": []
}
}
And how Amazon Rekognition can analyse videos:
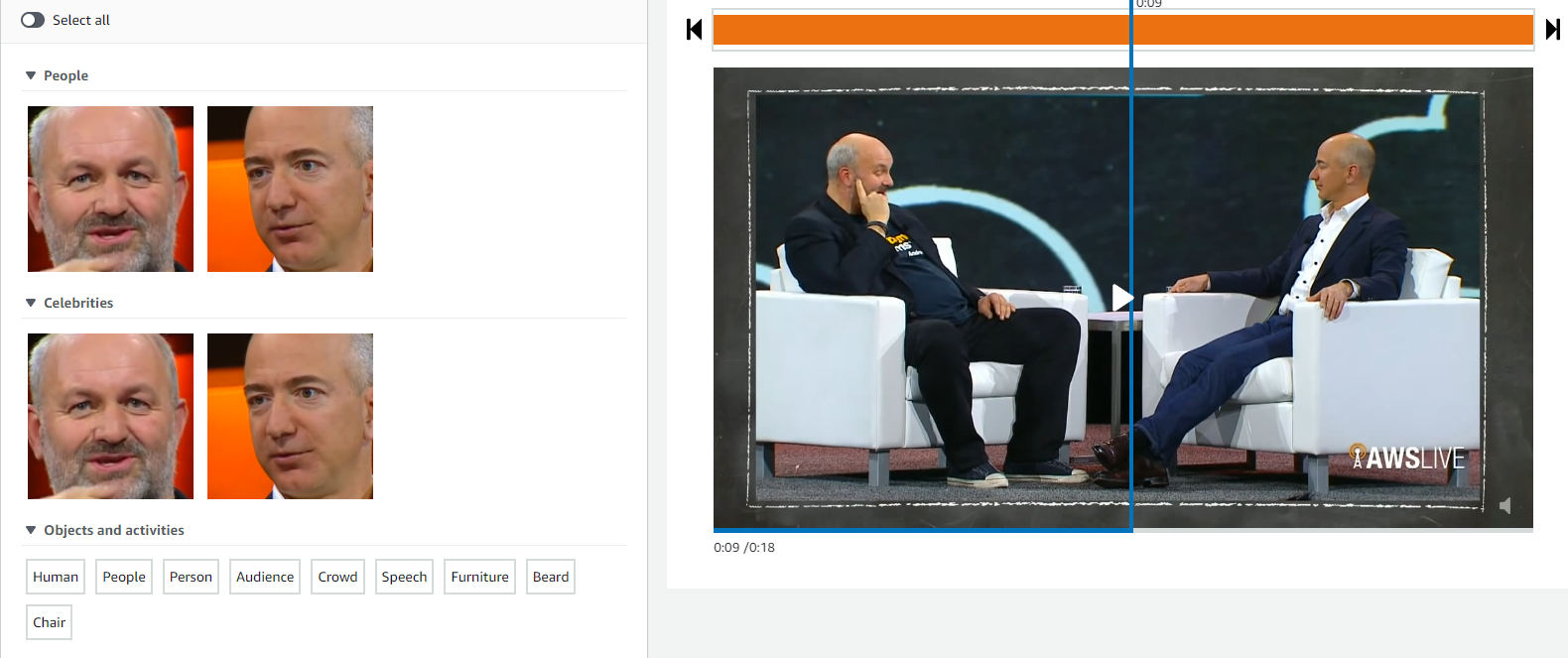
As a result of processing 18 seconds of video we get 22000 lines of Json file containing timestamps and detected people and objects:
...
{
"Celebrity":{
"BoundingBox":{
"Height":0.793055534362793,
"Left":0.17265625298023224,
"Top":0.13611111044883728,
"Width":0.637499988079071
},
"Confidence":100,
"Id":"23iZ1oP",
"Name":"Werner Vogels",
"Urls":[
]
},
"Timestamp":12245
},
...
As part of the AWS Free Tier, you can get started with Amazon Rekognition Image for free. The free tier period lasts 12 months.
During the free tier period you can analyze 5,000 images per month for free each, in Group 1 and Group 2 APIs and you can store 1,000 face metadata objects per month for free.
After that an image analysis will cost $0.001 per image for First 1 million images, $0.0008 per image for next 4 million images and so on.
Rekognition Video costs 0.10$ per minute of video per type of detection.
More or less real case of using Amazon Rekognition along with other AWS services can be as follows:
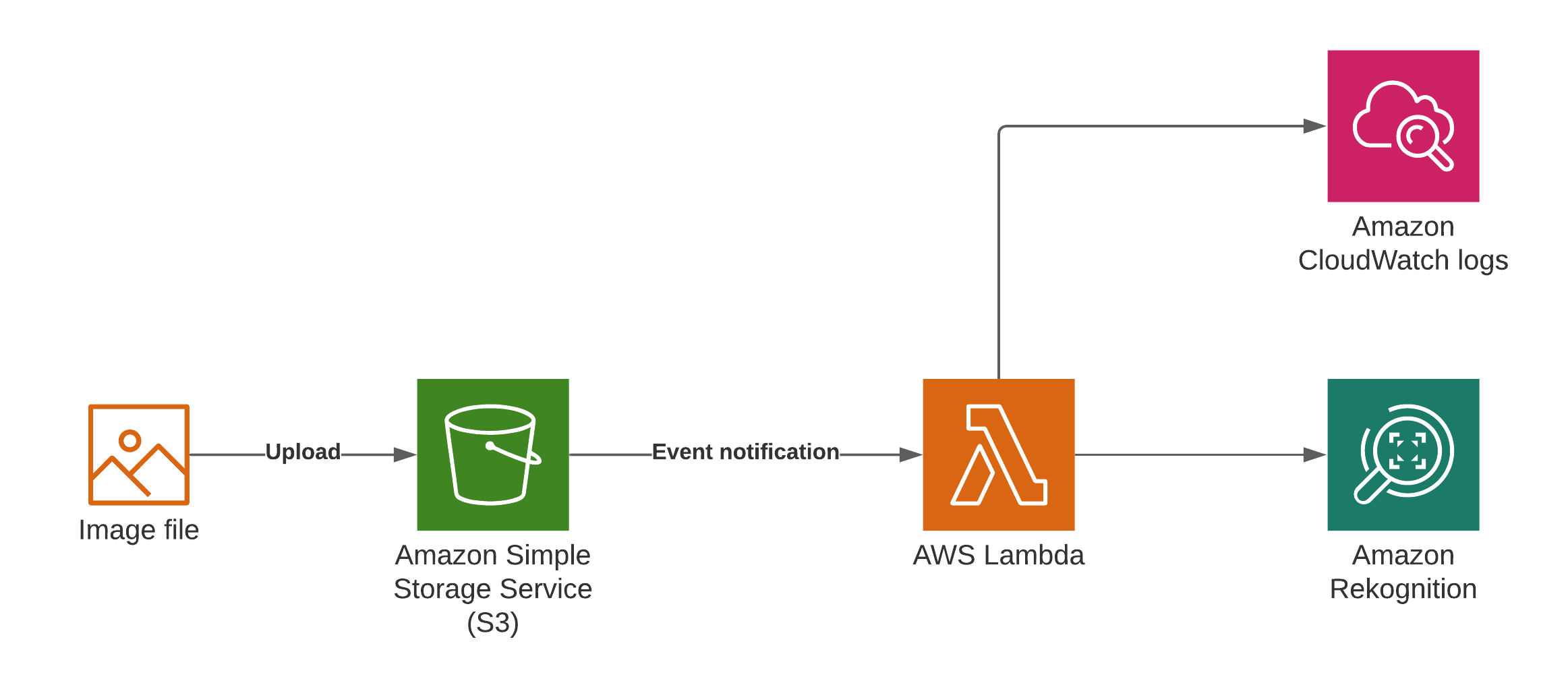
First of all we need to configure event notification for S3 bucket:
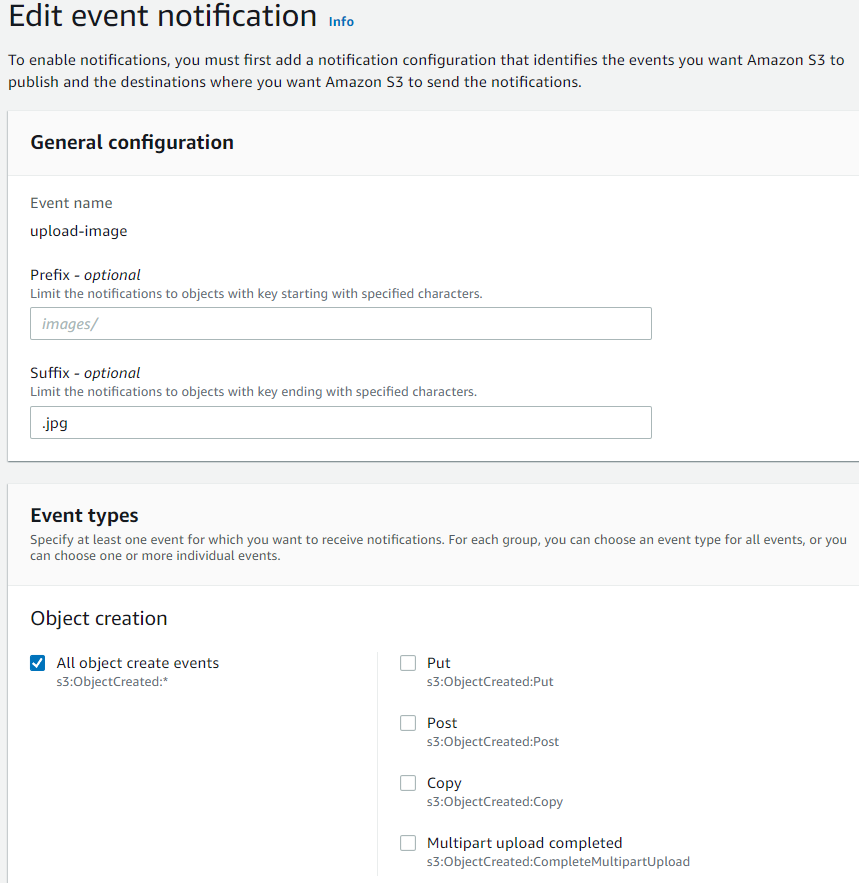
When we upload a “.jpg” file, the Lambda function will be triggered. Lambda code is below:
from __future__ import print_function
import boto3
def lambda_handler(event, context):
print("========Processing started=======")
# read the bucket name from the event
bucket_name=event['Records'][0]['s3']['bucket']['name']
# read the object from the event
image_name=event['Records'][0]['s3']['object']['key']
detect_labels(image_name,bucket_name)
print("Labels detected Successfully")
def detect_labels(image, bucket):
reko=boto3.client('rekognition')
response = reko.detect_labels(Image={'S3Object':{'Bucket':bucket,'Name':image}})
print('Detected labels for ' + image)
print('==============================')
for label in response['Labels']:
print ("Label: " + label['Name'])
print ("Confidence: " + str(label['Confidence']))
print ("Instances:")
for instance in label['Instances']:
print (" Bounding box")
print (" Top: " + str(instance['BoundingBox']['Top']))
print (" Left: " + str(instance['BoundingBox']['Left']))
print (" Width: " + str(instance['BoundingBox']['Width']))
print (" Height: " + str(instance['BoundingBox']['Height']))
print (" Confidence: " + str(instance['Confidence']))
print()
print ("Parents:")
for parent in label['Parents']:
print (" " + parent['Name'])
print ("----------")
print('==============================')
return response
Uploading the following image to the bucket:

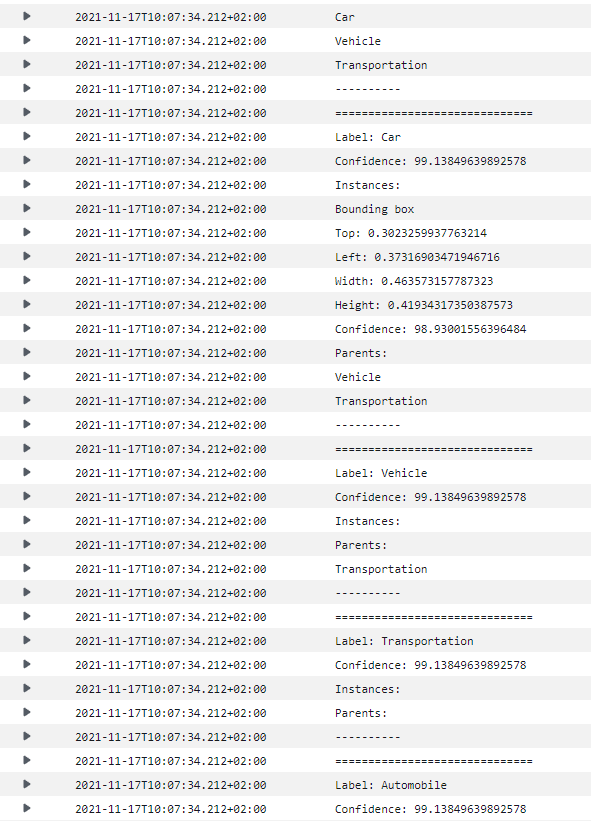
Checking CloudWatch Log group of the Lambda function:
Conclusion
In this post we have started looking at machine learning services in AWS. With SageMaker we can build, train and deploy ML models. We can either develop our own algorithms or use AWS built-in ones. There are many algorithms also available on the Marketplace. Rekognition does not require any knowledge in data science and machine learning. The model is already pre trained and we can just use it as a fully managed AWS service. According to our observations, the ML area is developing very fast by many big companies and startups. There are plenty of new healthcare and cyber-security applications based on machine and deep learning. In the next post we will continue with other ML services that may be pretty useful for business.
