

Automat-it is an all-in AWS Premier partner empowering startups with DevOps & FinOps expertise and hands-on services. We have guided and supported hundreds of startups to leverage AWS more effectively throughout their growth journey. As DevOps experts, we build cloud solutions from a DevOps perspective, focusing on practical applications with built-in efficiencies that save our customers significant time to market and optimize their cloud performance and economics.
With the Automat-it FinOps team, we maximize cloud investment ROI by making more informed cloud financial decisions, maintaining cloud cost efficiency, and ensuring well-controlled AWS environments.
Problem statement
We thoroughly analyze cloud costs to optimize and reduce them wherever possible. Hundreds of our customers may request thousands of changes/improvements to their AWS infrastructure. Here, we need to be proactive and understand which requests or tasks may lead to changes in cloud costs. Artificial intelligence (AI) is a great candidate to take on routine tasks, allowing engineers to focus more on interesting and important tasks.
One FinOps analyst is responsible for multiple customers, and manually checking all new tasks would be challenging for them, especially when they just need to know if the new task will affect cloud costs in any way.
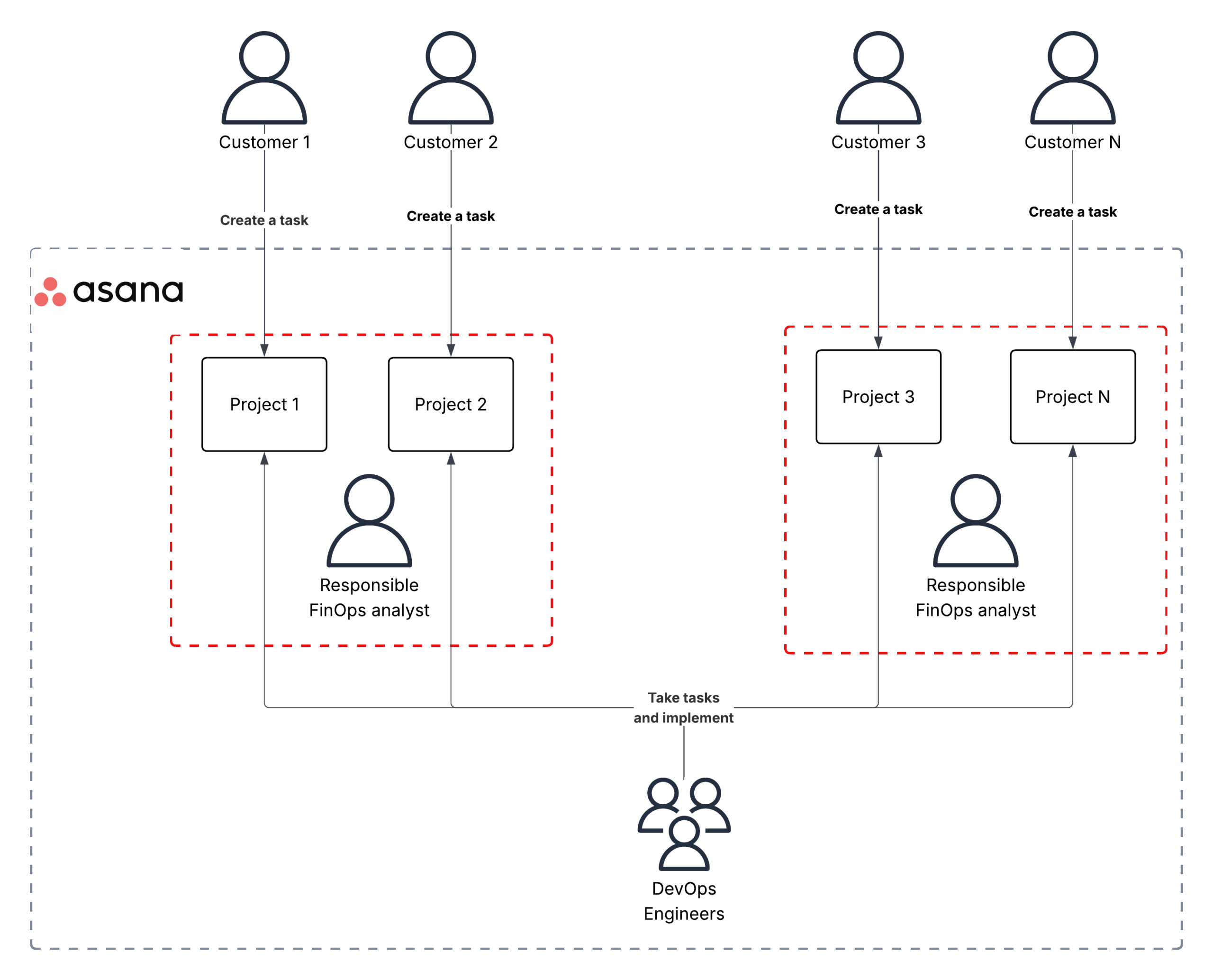
We have decided to implement an automatic task analysis and classification using AI, notifying the responsible FinOps analyst only about tasks that impact cloud costs.
Solution overview
Automat-it owns a Business Automation Software product called Albatross, which also works as a customer database, where we have all the needed contacts, including the responsible FinOps Analyst. This is our single source of truth.
Automat-it uses Asana, a work management platform designed to help teams organize, track, and manage their work. It allows teams to create projects, assign tasks, set deadlines, and collaborate in real-time.
Albatross and Asana have API, which can be used for the designed automation.
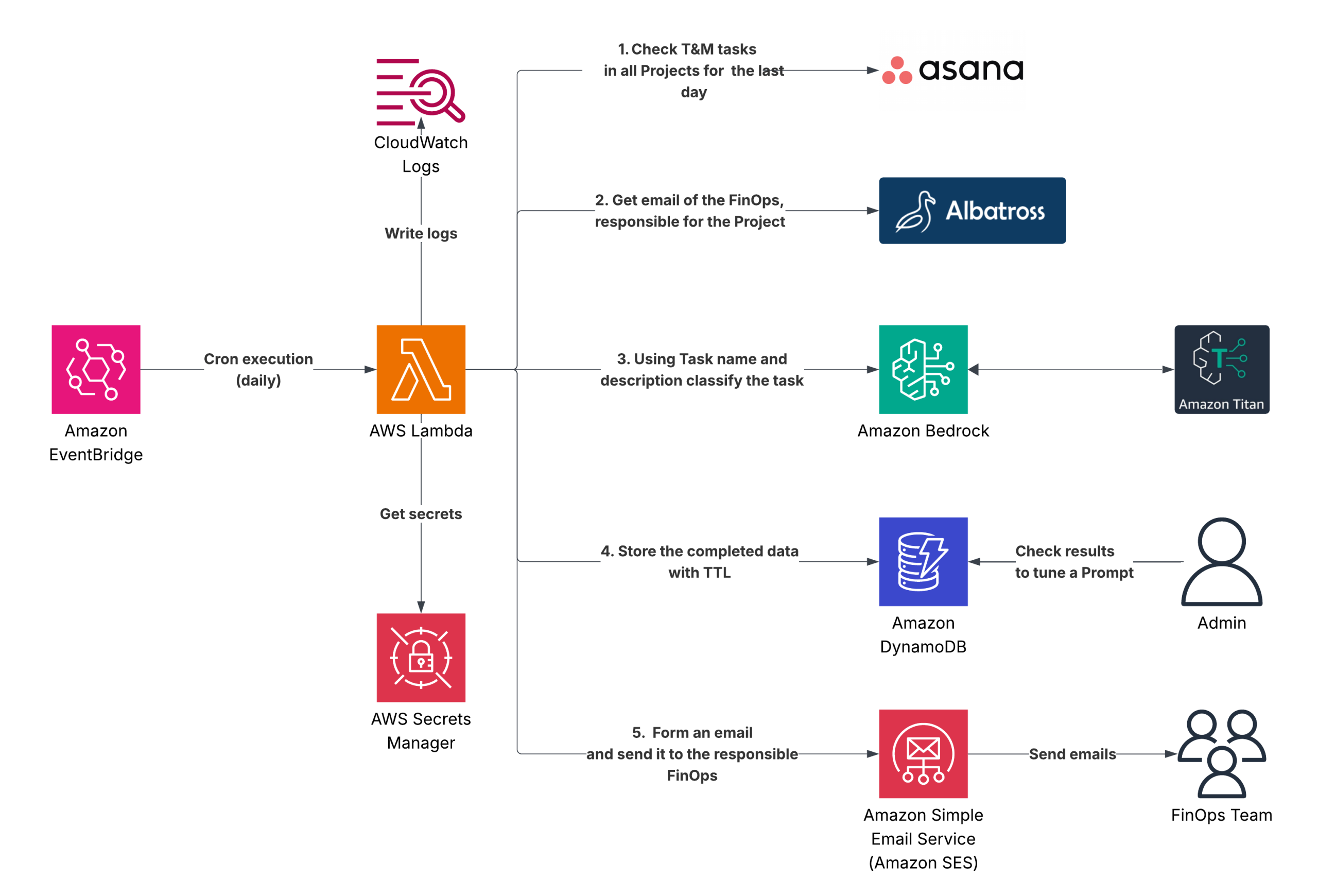
Lambda checks new T&M tasks in Asana daily, analyzes them via Amazon Bedrock to classify if the changes affect cloud costs. If found, an email notification is sent to the relevant FinOps. The responsible FinOps is retrieved from the Albartoss API.
How it works
- Lambda function is executed daily via an Amazon EventBridge scheduled rule
- It gets credentials for Asana and Albatross from the AWS Secrets Manager secret
- It checks all Asana tasks for Time & Material (T&M) projects for the last 1 day
- It utilizes the Albatross API to retrieve the email address of the FinOps responsible for each project. If the email address cannot be found for some reason, the FinOps Team Lead will be used as the email recipient
- It utilizes Amazon Bedrock to categorize every task, distinguishing between “FinOps” and “Not FinOps”, indicating whether the task may result in cloud cost changes or not. Lambda attempts 10 calls to Amazon Bedrock to overcome throttling
- All collected data is stored in a DynamoDB table with the following attributes:
- customer_finOpsEmail -> FinOps email got from the Albatross
- Classification -> “FinOps” or “Not FinOps”
- TaskName -> task name from Asana
- ProjectName -> project name from Asana
- LinkToAsanaTask -> The link will be helpful in the final email report
- Explanation -> Why did the Amazon Bedrock model make such a decision?
- TaskGID -> task ID from Asana
- expireAt -> Unix epoch timestamp, needed for DynamoDB TTL. By default, we store data for the last 23 hours (a bit less than the period of task checking)
- The final step – Lambda aggregates data on “FinOps” tickets for each FinOps engineer and sends an email to each of them. If the email cannot be delivered for any reason, it will be resent to the FinOps Team Lead
We store data in DynamoDB for future needs or more convenient debugging today. If, in the future, we have so many T&M tasks per day that Lambda cannot complete the task classification within 15 minutes (the hard limit for Lambda execution), we can split the logic into several Lambda functions. The DynamoDB data can also be used for visualization, if needed.
Lambda Code
import requests
import boto3
import json
import time
import re
import os
from datetime import datetime, timedelta, timezone
import logging
from collections import defaultdict
from botocore.exceptions import ClientError
# === CONFIG FROM ENVIRONMENT ===
MODEL_ID = os.environ['MODEL_ID']
DYNAMODB_TABLE = os.environ['DYNAMODB_TABLE']
DAYS_TO_CHECK = int(os.environ.get('DAYS_TO_CHECK', '1'))
TTL_HOURS = int(os.environ.get('TTL_HOURS', '23'))
REGION = os.environ['AWS_REGION']
DEFAULT_FINOPS_EMAIL = os.environ['DEFAULT_FINOPS_EMAIL']
SES_SENDER_EMAIL = os.environ['SES_SENDER_EMAIL']
SUPPORT_EMAIL = os.environ['SUPPORT_EMAIL']
# === LOGGING ===
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
for handler in logger.handlers[:]:
logger.removeHandler(handler)
handler = logging.StreamHandler()
handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(levelname)s: %(message)s')
handler.setFormatter(formatter)
logger.addHandler(handler)
# === CLIENTS ===
bedrock = boto3.client(service_name='bedrock-runtime', region_name=REGION)
dynamodb = boto3.resource('dynamodb', region_name=REGION)
table = dynamodb.Table(DYNAMODB_TABLE)
secretsmanager = boto3.client("secretsmanager", region_name=REGION)
ses = boto3.client("ses", region_name=REGION)
# === GET SECRETS (including parameters from secret) ===
secret_name = os.environ['ASANA_ALBATROSS_SECRET']
secrets = secretsmanager.get_secret_value(SecretId=secret_name)
secret_dict = json.loads(secrets['SecretString'])
ASANA_ACCESS_TOKEN = secret_dict['asana_access_token']
ALBATROSS_USERNAME = secret_dict['albatross_username']
ALBATROSS_PASSWORD = secret_dict['albatross_password']
WORKSPACE_GID = secret_dict['workspace_gid']
ALBATROSS_API_URL = secret_dict['albatross_api_url']
HEADERS = {"Authorization": f"Bearer {ASANA_ACCESS_TOKEN}"}
PROMPT_TEMPLATE = """
You are an AI assistant tasked with classifying Asana tickets as either **FinOps** or **Not FinOps**.
Definitions:
- FinOps = tasks related to cloud financial operations, cost optimization, resource usage, budgeting, chargeback/showback, OR any technical task that directly affects cloud costs (such as changing storage size, instance type, scaling settings, deleting unused resources, or managing pricing agreements).
- Not FinOps = tasks unrelated to financial operations or cost-impacting technical changes (e.g., general technical maintenance, feature development, documentation).
Examples:
- Deleting old environments / unused infra → FinOps
- Investigating idle resources (e.g., NAT Gateway) → FinOps
- Renewing Private Pricing Addendum (PPA) → FinOps
- Reducing log volume in monitoring → FinOps
- Upgrading platform versions without cost impact → Not FinOps
- Converting to Terraform/IaC alone → Not FinOps unless cost reduction is a goal
Instructions:
- ONLY respond with a valid JSON object. No other text.
- Your response MUST look exactly like this:
{{"Classification":"FinOps","Explanation":"Reason for the classification"}}
Input:
{ticket_content}
"""
# === Albatross Auth ===
class Albatross:
def __init__(self, username: str, password: str, url: str):
self.albatross = requests.Session()
self.base_url = url
self.auth(username, password)
def auth(self, username, password):
response = self.albatross.post(
url=f'{self.base_url}/auth/local',
json={'identifier': username, 'password': password},
)
if response.status_code != 200:
raise Exception(f'Failed to authenticate in Albatross: {response.status_code} - {response.content}')
self.albatross.headers = {'Authorization': f"Bearer {response.json()['jwt']}"}
def get_finops_email(self, customer_prefix: str) -> str:
variations = [
customer_prefix,
customer_prefix.lower(),
customer_prefix.upper(),
customer_prefix.title(),
]
for prefix in variations:
response = self.albatross.get(
url=f'{self.base_url}/aws-account/support-info',
params={'customer_name[$contains]': prefix},
)
if response.status_code == 200:
data = response.json()
emails = {entry['customer_finOpsEmail'] for entry in data if entry.get('customer_finOpsEmail')}
if emails:
return sorted(emails)[0]
logger.warning(f"Could not find finOps email for: {customer_prefix}")
return ""
# === Utility Functions ===
def safe_get_next_page(data):
next_page_data = data.get("next_page")
return next_page_data.get("offset") if next_page_data else None
def extract_customer_prefix(project_name):
base = project_name.split("|")[0].strip()
for delimiter in [".", "-", " "]:
if delimiter in base:
base = base.split(delimiter)[0].strip()
break
return base
def get_projects():
url = "https://app.asana.com/api/1.0/projects"
params = {"workspace": WORKSPACE_GID, "archived": False, "limit": 100}
projects = []
while True:
r = requests.get(url, headers=HEADERS, params=params)
if r.status_code != 200:
logger.error(f"Error: {r.status_code} {r.text}")
break
data = r.json()
for p in data["data"]:
if "T&M" in p.get("name", ""):
projects.append({"gid": p["gid"], "name": p.get("name", "Unnamed Project")})
if not (offset := safe_get_next_page(data)):
break
params["offset"] = offset
return projects
def get_recent_tasks(project_gid):
url = f"https://app.asana.com/api/1.0/projects/{project_gid}/tasks"
params = {"opt_fields": "name,created_at", "limit": 100}
tasks = []
start_time = datetime.now(timezone.utc) - timedelta(days=DAYS_TO_CHECK)
while True:
r = requests.get(url, headers=HEADERS, params=params)
if r.status_code != 200:
logger.error(f"Error fetching tasks: {r.status_code} {r.text}")
break
data = r.json()
for t in data["data"]:
created_at = datetime.fromisoformat(t["created_at"].replace('Z', '+00:00'))
if created_at >= start_time:
tasks.append({"gid": t["gid"], "name": t["name"], "created_at": created_at})
if not (offset := safe_get_next_page(data)):
break
params["offset"] = offset
return tasks
def get_task_details(task_gid):
url = f"https://app.asana.com/api/1.0/tasks/{task_gid}"
params = {"opt_fields": "name,notes,projects.name,tags.name"}
r = requests.get(url, headers=HEADERS, params=params)
if r.status_code != 200:
logger.warning(f"Error fetching task {task_gid}")
return None
data = r.json()["data"]
return {
"title": data.get("name", ""),
"description": data.get("notes", "")[:500],
"tags": [tag["name"] for tag in data.get("tags", [])],
"projects": [p["name"] for p in data.get("projects", [])]
}
def extract_first_valid_json(text):
matches = re.findall(r'\{.*?\}', text, re.DOTALL)
for match in matches:
try:
data = json.loads(match)
if "Classification" in data and "Explanation" in data:
return data
except json.JSONDecodeError:
continue
return None
def classify_ticket(details):
ticket_input = {
"Ticket Title": details["title"],
"Description": details["description"],
"Metadata": f"Project: {', '.join(details['projects'])}, Tags: {', '.join(details['tags'])}"
}
body = json.dumps({
"inputText": PROMPT_TEMPLATE.replace("{ticket_content}", json.dumps(ticket_input, indent=2)),
"textGenerationConfig": {"maxTokenCount": 300, "temperature": 0.0, "topP": 1}
})
for attempt in range(10):
try:
res = bedrock.invoke_model(
body=body,
contentType="application/json",
accept="application/json",
modelId=MODEL_ID
)
text = json.loads(res['body'].read()).get('results', [{}])[0].get('outputText', '')
return extract_first_valid_json(text) or {"Classification": "Unknown", "Explanation": "Could not parse"}
except ClientError as e:
if e.response['Error']['Code'] == 'ThrottlingException':
time.sleep(2 ** attempt)
else:
raise
return {"Classification": "Unknown", "Explanation": "Max retries exceeded"}
def store_in_dynamodb(task_gid, task_name, project_name, project_gid, classification, explanation, finops_email):
finops_email = finops_email or DEFAULT_FINOPS_EMAIL
expire_at = int((datetime.utcnow() + timedelta(hours=TTL_HOURS)).timestamp())
table.put_item(Item={
"customer_finOpsEmail": finops_email,
"Classification": classification,
"TaskName": task_name,
"ProjectName": project_name,
"LinkToAsanaTask": f"https://app.asana.com/0/{project_gid}/{task_gid}",
"Explanation": explanation,
"TaskGID": task_gid,
"expireAt": expire_at
})
def send_finops_emails():
response = table.scan()
items = response.get("Items", [])
grouped = defaultdict(lambda: defaultdict(list))
for item in items:
if item.get("Classification") == "FinOps":
email = item.get("customer_finOpsEmail", DEFAULT_FINOPS_EMAIL)
grouped[email][item["ProjectName"]].append(item)
for email, projects in grouped.items():
html = "<h2>T&M Tasks which may potentially affect cloud costs</h2>"
total_tasks = sum(len(tasks) for tasks in projects.values())
logger.info(f"📧 Preparing email for: {email} with {total_tasks} tasks")
for project, tasks in projects.items():
html += f"<h3>{project}</h3><ul>"
for task in tasks:
html += f"<li><a href='{task['LinkToAsanaTask']}'>{task['TaskName']}</a>: {task['Explanation']}</li>"
html += "</ul>"
try:
ses.send_email(
Source=SES_SENDER_EMAIL,
Destination={
"ToAddresses": [email],
"CcAddresses": [SUPPORT_EMAIL]
},
Message={
"Subject": {"Data": "FinOps Task Summary"},
"Body": {"Html": {"Data": html}}
}
)
logger.info(f"✅ Email successfully sent to {email} (CC: {SUPPORT_EMAIL})")
except ClientError as e:
logger.warning(f"❌ Failed to send email to {email}: {e.response['Error']['Message']}. Falling back to DEFAULT_FINOPS_EMAIL.")
try:
ses.send_email(
Source=SES_SENDER_EMAIL,
Destination={
"ToAddresses": [DEFAULT_FINOPS_EMAIL],
"CcAddresses": [SUPPORT_EMAIL]
},
Message={
"Subject": {"Data": f"Failed to send to {email}"},
"Body": {"Html": {"Data": html}}
}
)
logger.info(f"📨 Email sent to fallback: {DEFAULT_FINOPS_EMAIL} (CC: {SUPPORT_EMAIL})")
except ClientError as fallback_error:
logger.error(f"❌ Failed to send fallback email to {DEFAULT_FINOPS_EMAIL}: {fallback_error.response['Error']['Message']}")
def lambda_handler(event=None, context=None):
albatross = Albatross(ALBATROSS_USERNAME, ALBATROSS_PASSWORD, ALBATROSS_API_URL)
projects = get_projects()
for p in projects:
client_prefix = extract_customer_prefix(p["name"])
finops_email = albatross.get_finops_email(client_prefix)
logger.info(f"\n📌 Processing project: {p['name']} (client prefix: {client_prefix})")
tasks = get_recent_tasks(p["gid"])
if not tasks:
logger.info(" No recent tasks.")
continue
for t in tasks:
logger.info(f" 🔹 Task: {t['name']} ({t['created_at'].strftime('%Y-%m-%d %H:%M')})")
details = get_task_details(t["gid"])
if not details:
continue
result = classify_ticket(details)
classification = result.get("Classification", "Unknown")
explanation = result.get("Explanation", "N/A")
logger.info(f" → {classification}: {explanation}")
store_in_dynamodb(t["gid"], t["name"], p["name"], p["gid"], classification, explanation, finops_email)
time.sleep(1)
send_finops_emails()
if __name__ == "__main__":
lambda_handler()
If the result of classification is not acceptable, we can modify the Prompt (“PROMPT_TEMPLATE” in the Lambda code) or change the Bedrock model.
Results
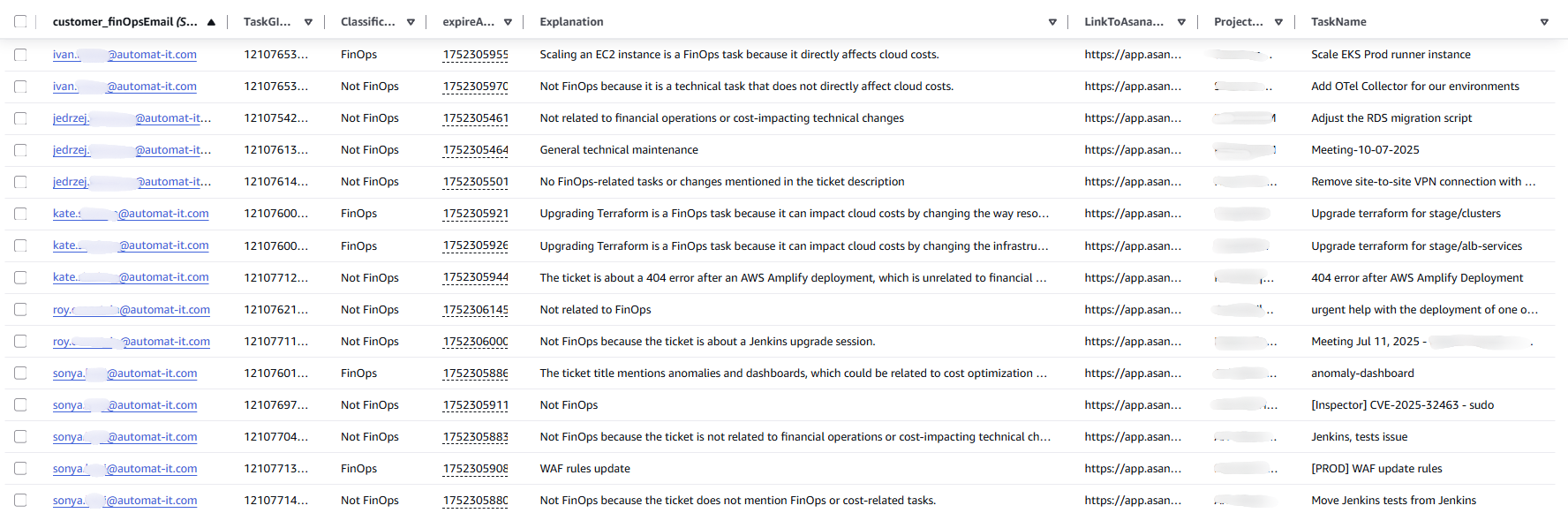
Tasks for the last 24 hours were written into the DynamoDB table. We can see the Project, task, classification, explanation, and the responsible FinOps analyst. Data for the previous day was automatically removed by DynamoDB TTL.
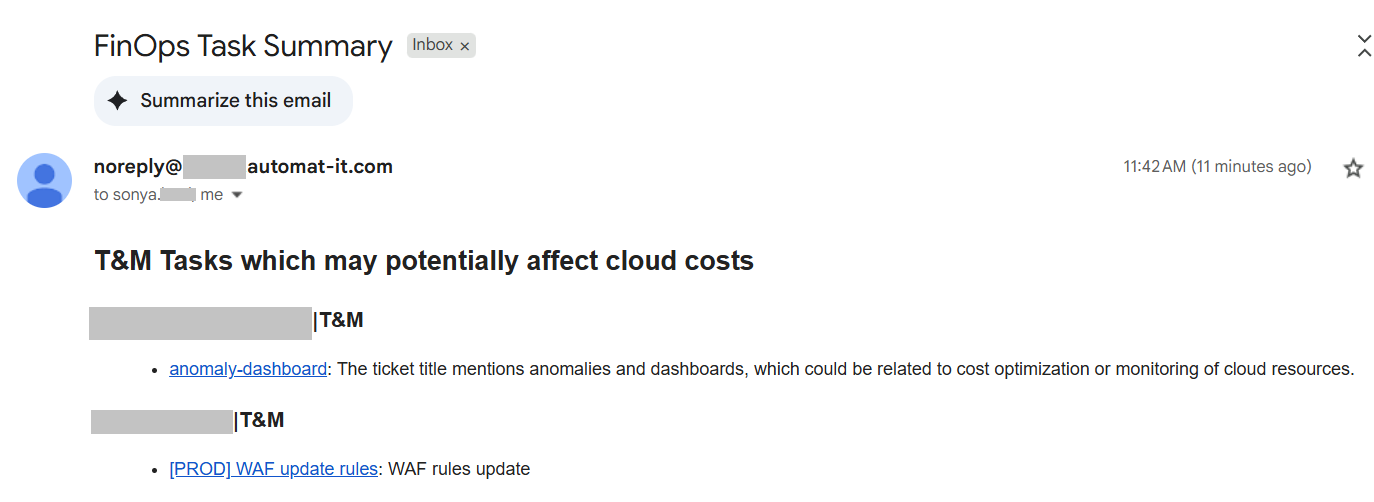
Emails have been sent mentioning only “FinOps” tasks (tasks that potentially may affect cloud costs).
Conclusion
In this blog, we demonstrated how leveraging Amazon Bedrock’s generative AI capabilities alongside AWS services like AWS Lambda, Amazon DynamoDB, and Amazon SES can revolutionize cloud cost monitoring and FinOps practices. By integrating Amazon Bedrock’s foundation models into FinOps workflows, organizations gain not just cost visibility but also proactive insights and recommendations, laying the foundation for more informed budgeting, spending control, and cloud financial governance.
