

About Marshmallow
Marshmallow, a company offering fair car insurance deals to thousands of customers in the UK, is exploring new ways to enhance its data management strategies. They’re focusing on transitioning from a manually-managed feature store to a more advanced automated system.
Their goal? To improve efficiencies, reduce redundant computations, and enhance their proprietary pricing and fraud models.
The Challenge
Marshmallow’s existing system faces multiple challenges that impact its efficiency and effectiveness. Firstly, the complexity of feature versioning often results in computing features repeatedly across different models without the need for it. Additionally, any modifications to features or the feature store require redeploying models, disrupting continuous operations.
While the current system includes versioning of the feature store, Marshmallow seeks a more robust architecture to avoid potential conflicts and ensure system robustness and scalability.
The Solution
Marshmallow is evaluating two potential solutions: Feast and Amazon SageMaker Feature Store. They are specifically looking for a feature store that supports data lineage and can be used to perform transformations on the fly and provide real-time access to online features. The ideal system would allow features to be updated without the necessity of redeploying SageMaker-hosted endpoints. Additionally, it should facilitate transformations efficiently without the need to store these transformations within the Feature Store.
The solution: Amazon SageMaker Feature Store
Automat-It has proposed a solution to address Marshmallow’s challenges by implementing the Amazon SageMaker Feature Store. This system will store raw, untransformed “vanilla” values. All access to these values will be managed through a Data Access Layer (DAL), which will apply necessary transformations on retrieval.
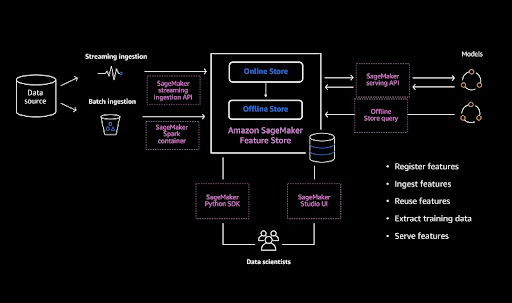
[Image from AWS Blog]
- SageMaker Feature Store offers both streaming and batch ingestion methods for data. Streaming ingestion uses the PutRecord API and can be parallelized for higher throughput, while batch ingestion can be integrated with feature generation and processing pipelines.
- Real-time data access is provided through the low-latency GetRecord API, which can also be parallelized for high-throughput applications.
- The offline store is an S3 bucket in the user’s account, allowing for the use of query engines like Athena and open-source tools like Presto. The AWS Glue Data Catalog is automatically built for feature groups during creation.
- Advanced query patterns, such as time-travel queries, are supported by the SageMaker Feature Store design.
- SageMaker Feature Store provides end-to-end encryption at rest and in transit, with the option to use different CMKs for online and offline stores. Fine-grained access control is also available through IAM user roles and policies.
The project scope
The scope of this project includes several key deliverables. Initially, we will establish an AWS account and set up the SageMaker Feature Store. Subsequent steps include ingesting files into the store and populating it with sample data. We will also develop proof-of-concept (POC) code to handle data transformations.
Additionally, testing these transformations to evaluate latency is an integral part of this project, ensuring that our solutions meet performance benchmarks efficiently.
Unlocking the benefits of Amazon SageMaker Feature Store
- Improved efficiency: SageMaker Feature Store streamlines workflows and reduces manual interventions, enabling data scientists to focus more on experimentation and model innovation.
- Model training and deployment flexibility: SageMaker Feature Store enhances flexibility throughout the model lifecycle, providing easy access to historical feature values and enabling seamless model updates.
- Historical data access and time-travel queries: SageMaker Feature Store empowers data scientists to retrieve historical feature values efficiently, enabling time-travel queries and facilitating experimentation with different feature combinations.
- Enhanced collaboration and governance: The Feature Store supports secure cross-account access via AWS Resource Access Manager (RAM), promoting collaboration, feature sharing, and governance practices.
- Scalability and reliability: Built on AWS’s infrastructure, SageMaker Feature Store ensures exceptional scalability and reliability for production use cases.
Technical deep dive: unlocking the power of Amazon SageMaker Feature Store
Key capabilities: why Amazon SageMaker stands out
- Feature Store as a service: Amazon SageMaker provides a fully managed feature store, eliminating manual management and reducing operational overheads.
- Data lineage and transformation: The Feature Store tracks data lineage, ensuring transparency and compliance. It also supports dynamic transformations during retrieval, enabling efficient feature engineering.
- Online and offline store: Amazon SageMaker offers both online and offline stores. The Online store provides low-latency, real-time access to the latest features, while the Offline store optimizes large-scale, batch data processing.
- Cross-account sharing: with cross-account sharing via AWS Resource Access Manager(RAM), SageMaker enhances collaboration and governance, allowing secure access across teams and accounts.
Technical example: adding features to an existing feature group
Let’s consider a scenario where Marshmallow wants to add new features to an existing feature group. The example below demonstrates this process and additional requirements for versioning and accessing data from the Online Store.
import boto3
import pandas as pd
from sagemaker import Session
from sagemaker.feature_store.feature_group import FeatureGroup
# Get the SageMaker session and client
session = boto3.Session()
sagemaker_client = session.client(service_name=‘sagemaker’)
sagemaker_session = Session(boto_session=session)
# Define the existing feature group name
feature_group_name = ‘marshmallow-data-model’
# Add new feature definitions to the feature group
feature_defs = [
{‘FeatureName’: ‘vehicle-id’, ‘FeatureType’: ‘String’}, # Primary key
{‘FeatureName’: ‘timestamp’, ‘FeatureType’: ‘String’}, # Event time
{‘FeatureName’: ‘feature_a’, ‘FeatureType’: ‘Categorical’},
{‘FeatureName’: ‘feature_b’, ‘FeatureType’: ‘Integral’}
]
# Update the feature group
sagemaker_client.update_feature_group(
FeatureGroupName=feature_group_name,
RecordIdentifierFeatureName=‘vehicle-id’,
EventTimeFeatureName=‘timestamp’,
FeatureDefinitions=feature_defs
)
# Read a sample dataframe from a CSV file
csv_file_path = ‘sample_data.csv’ # Replace with the path to your CSV file
df = pd.read_csv(csv_file_path)
# Connect to the feature group using SageMaker SDK
feature_group = FeatureGroup(name=feature_group_name, sagemaker_session=sagemaker_session)
# Ingest sample data with new features
feature_group.ingest(data_frame=df, max_workers=16, max_processes=16, wait=True)
In this example, Marshmallow adds two new features, ‘feature_a’ and ‘feature_b’, to the feature group ‘marshmallow-data-model’.
RecordIdentifierFeatureName: This is the feature group’s primary key, uniquely identifying each record. In this example, ‘vehicle-id’ is used as the unique identifier for each record.
EventTimeFeatureName: This feature is used for versioning and is required for the Online Store functionality. It indicates when the event occurred and helps determine which feature records are the latest to be retrieved. In this example, ‘timestamp’ serves this purpose.
CSV File Structure: Ensure your CSV file contains columns from “feature_defs”: ‘vehicle-id’, ‘timestamp’, ‘feature_a’, and ‘feature_b’.
Efficient Ingestion Time: The ‘max_workers’ and ‘max_processes’ parameters can be optimized to improve ingestion time, depending on the available compute resources. If your system is equipped with ample CPU cores and memory, increasing these values can expedite the ingestion process. Conversely, if resources are limited, you may need to reduce these values to avoid overwhelming your system.
Achieving low latency with the Online Store
Amazon SageMaker Feature Store now offers a fully managed, in-memory online store powered by ElastiCache for Redis, enabling real-time feature retrieval for high-throughput machine-learning applications. This new online store can be selected when creating a feature group and allows for familiar SageMaker APIs to read and write data. Key capabilities include time-to-live (TTL) for managing storage size, CloudTrail logs for monitoring API calls, and CloudWatch metrics for tracking performance. SageMaker handles infrastructure tasks such as scaling, availability, and security, relieving users from these operational concerns.
Here’s an example of retrieving features from the Online Store:
import boto3
from sagemaker.feature_store.feature_group import FeatureGroup
# Get the SageMaker session
session = boto3.Session()
# Define the feature group name
feature_group_name = ‘marshmallow-data-model’
# Load the feature group
feature_group = FeatureGroup(name=feature_group_name, sagemaker_session=session)
# Define the feature names to retrieve
feature_names = [‘feature_a’, ‘feature_b’]
# Retrieve the latest value for the specified features
feature_values = feature_group.get_record(
record_identifier_value=‘vehicle-id’,
feature_names=feature_names
)
# Access the retrieved feature values
for feature_name, feature_value in feature_values.items():
print(f’Feature Name: {feature_name}, Value: {feature_value}’)
In this code snippet, Marshmallow retrieves the latest values for ‘feature_a’ and ‘feature_b’ for a specific record identifier (‘vehicle-id’). The get_record method ensures they access the most up-to-date data for accurate model inference.
Online Store capabilities and latency optimization
The Online Store in Amazon SageMaker Feature Store offers several advantages to achieve low latency:
- Real-time data access: the online Store provides immediate access to the latest features, ensuring that models always have current data.
- Optimized data storage: efficient data storage and indexing techniques are employed for low-latency retrieval.
- Scalability: built on AWS infrastructure, the Online Store handles high concurrency and scales seamlessly.
- Data partitioning: data is partitioned based on ingestion time, enabling faster retrieval and improved query performance.
- In-memory caching: frequently accessed features are cached in memory for ultra-low latency.
The Results
To conclude, adopting the Amazon SageMaker Feature Store is expected to improve Marshmallow’s data management capabilities and infrastructure and deliver several technical and commercial benefits:
Faster time to market: Streamlined data workflows can significantly reduce the time it takes to prepare and analyze data. This allows Marshmallow to act on insights quicker, identify trends faster, and release new features or products more rapidly.
Data-driven decision making: Easier access to clean, reliable data empowers Marshmallow to make data-driven decisions across all aspects of the business. This can lead to better product development, more effective marketing campaigns, and improved customer targeting.
Improved personalization: With a centralized feature store, Marshmallow can gain a deeper understanding of their customers and personalize their experiences. This can result in increased customer satisfaction, loyalty, and ultimately, revenue growth.
Reduced costs: Efficient data management can lead to significant cost savings. By streamlining data workflows and eliminating redundancies, Marshmallow can free up resources to invest in other areas of the business.
Enhanced innovation: Easier access to data can fuel innovation at Marshmallow. With a centralized store of features, data scientists and analysts can spend less time wrangling data and more time developing new insights and solutions.