

By Claudiu Bota, Sr. Solutions Architect, and Vitalii Vlasov, DevOps Engineer, Automat-it – AWS Premier Tier Partner
In today’s AI-driven technology landscape, organizations face a critical challenge: securing sufficient GPU resources while maintaining cost efficiency and operational resilience.
The explosive growth in AI development has created unprecedented demand for these specialized processors, resulting in global shortages and skyrocketing costs. According to Stanford’s 2024 AI Index Report, the computational requirements for training state-of-the-art AI models have been doubling every 6 months, far outpacing Moore’s Law.
Meanwhile, the stakes couldn’t be higher, as AI training jobs that run for days or weeks can be devastated by infrastructure failures, potentially losing weeks of progress and valuable resources.
The GPU Challenge in Modern AI Development
The current AI boom has transformed GPUs from specialized gaming hardware into the lifeblood of machine learning operations. Organizations building AI solutions face three interconnected challenges:
- Scarcity: Global GPU shortages make capacity planning difficult
- Cost Pressure: Increasing prices for high-performance computing resources
- Resilience Requirements: The devastating impact of failures during long-running training jobs
Consider the reality of training large-scale foundation models: orchestrating hundreds of high-end GPUs continuously for weeks, where a single hardware failure could force a complete restart, losing substantial progress and significant computational investment.
To address these challenges, Amazon SageMaker HyperPod, offers dedicated GPU clusters with substantial discounts in exchange for time commitments.
SageMaker HyperPod provides pre-configured clusters designed for distributed training of large AI models, delivering up to 40% faster model training, automated health monitoring, flexible framework support, and seamless AWS service integration. HyperPod’s automatic failure recovery mechanisms address the resilience challenge by automatically handling node failures and resuming training from the last checkpoint, protecting organizations from catastrophic losses.
On top of these native resilience capabilities, we wanted to offer our customers the ability to scale their AI workloads during peak demand periods. For that, we relied on HyperPod’s integration with Amazon Elastic Kubernetes Service (EKS) to leverage Kubernetes orchestration capabilities.
A Hybrid Solution for Maximum Flexibility
When one of our customers approached us with this exact challenge, they needed a solution that combined the cost-effectiveness and reliability of reserved GPU capacity with the flexibility to scale dynamically during peak periods. Their use case was particularly interesting: they ran continuous training jobs that needed to be always available, similar to how inference workloads require constant uptime.
Since both their training and inference workloads required similar GPU specifications (A100 GPUs with 40-80GB memory), and their training pipeline operated 24/7 with continuous model updates and refinements, it made economic sense to use a unified infrastructure rather than maintaining separate environments.
We designed a hybrid architecture that leverages the strengths of both Amazon SageMaker HyperPod and Amazon EKS with Karpenter (a flexible, high-performance Kubernetes cluster autoscaler):
- SageMaker HyperPod: Provides the baseline GPU capacity with discounted pricing through long-term commitments via Flexible Training Plans, ensuring constant availability for core workloads. Its pre-configured clusters are optimized for distributed training, offering built-in resilience and monitoring capabilities that are crucial for long-running jobs.
- Amazon EKS with Karpenter: Delivers dynamic autoscaling capabilities to handle burst workloads during peak demand periods. Karpenter is an open-source project that automates provisioning and deprovisioning of Kubernetes nodes based on the specific scheduling needs of pods, allowing efficient scaling and cost optimization. It is fully supported by EKS as documented in AWS best practices. We chose this solution because it provides just-in-time provisioning, supports diverse instance types and purchasing options (spot, on-demand), and can scale to zero when not needed.
Implementation Details: Bridging Two Worlds
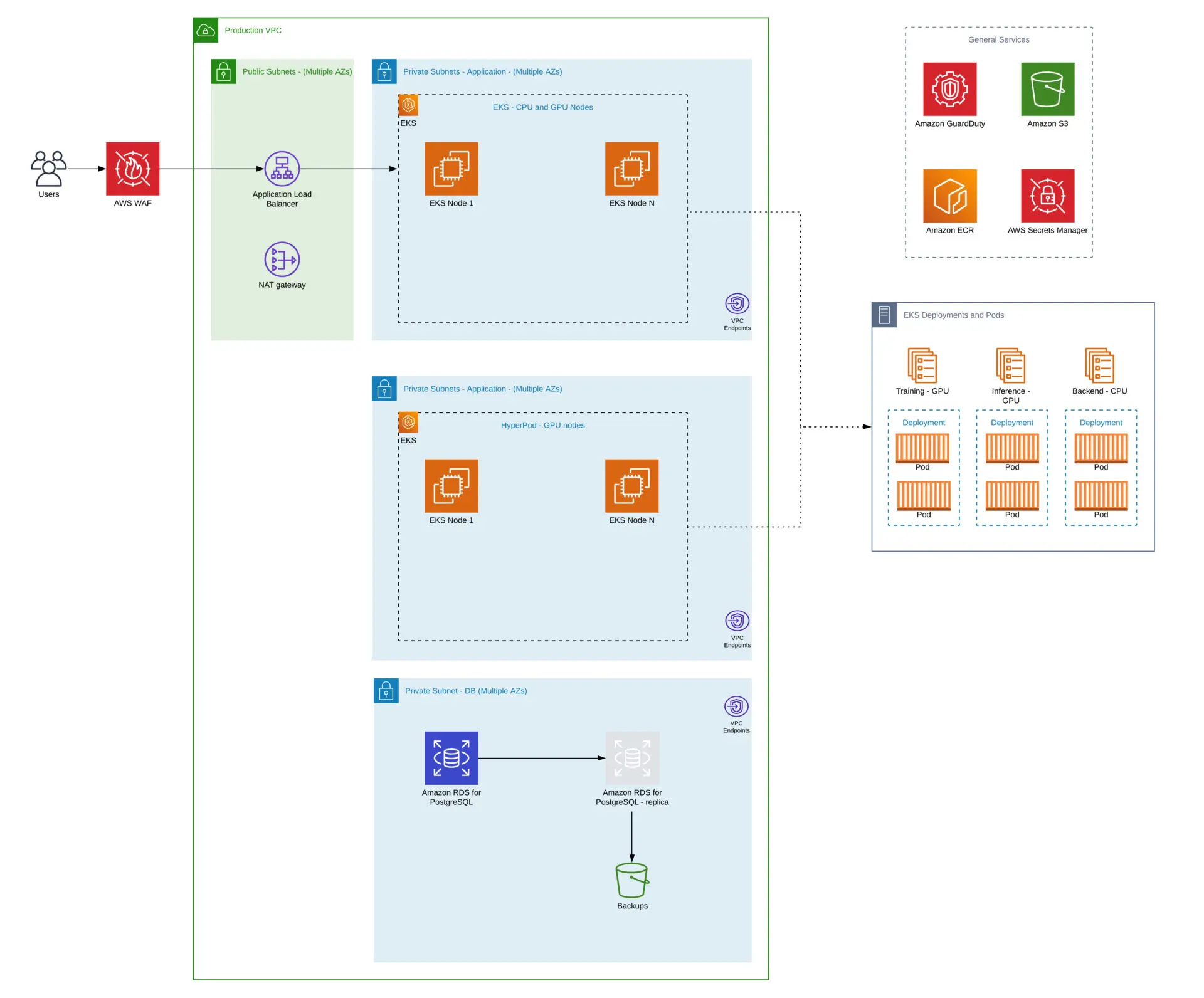
The architecture integrates three key components into a unified platform. At its core, the customer’s existing backend application runs on Amazon EKS with an RDS database, serving as the orchestration layer that initiates both training and inference jobs based on business logic and user requests. When the backend triggers a new job, it submits it through the Kubernetes API, where our configured node selectors and priority classes automatically route it to the appropriate infrastructure.
The SageMaker HyperPod cluster provides the reserved GPU capacity for baseline workloads, while the EKS cluster with Karpenter handles burst capacity by dynamically provisioning additional nodes when needed. Both environments share Amazon S3 for storage, ensuring seamless data availability regardless of where jobs execute.
This design allows the customer to maintain their existing application architecture while adding intelligent GPU resource management without any changes to their backend code.
The implementation required careful architecture design to create a seamless experience across both environments. For example, during a typical day, routine model training jobs triggered by the backend would run on the cost-effective HyperPod baseline capacity, but when urgent training or inference requests spike during business hours or a critical model needs rapid iteration, the system automatically provisions additional EKS resources to handle the burst while keeping costs optimal. Our solution includes:
- Unified Job Scheduling: We leverage Kubernetes native node selectors and priority classes to intelligently route workloads to either HyperPod or EKS based on resource availability, priority, and cost considerations. By properly configuring node labels and selection rules, the standard Kubernetes scheduler automatically places workloads on the most appropriate infrastructure without requiring custom scheduling logic.
- Consistent Environment: The same Helm charts and container images run seamlessly on both HyperPod and EKS platforms with no modifications required. This standardization ensures workloads can execute identically regardless of destination, simplifying deployment and eliminating compatibility concerns.
- Centralized Monitoring: A unified observability layer that relies on Amazon CloudWatch to collect metrics and logs, with the SageMaker HyperPod task governance dashboard that provides visibility into GPU utilization, job status, and costs across the hybrid infrastructure. CloudWatch aggregates performance data, custom metrics, and application logs, enabling teams to see, for instance, that long-running training jobs utilize 80% of HyperPod capacity while EKS has dynamically scaled up 15 additional nodes to handle a sudden inference workload spike.
- Cost Optimization: We prioritize scheduling pods on reserved capacity instances secured through Flexible Training Plans, ensuring these cost-effective resources are fully utilized before scaling. Only when the reserved capacity is exhausted during demand spikes does the system provision additional on-demand or spot instances through EKS, keeping costs low while maintaining the flexibility to handle peak workloads.
Smart Workload Placement with Helm and Kubernetes Priorities
A critical component of our solution was implementing intelligent workload placement through Kubernetes priorities and a custom Helm chart. Helm is a package manager for Kubernetes that helps you define, install, and upgrade complex Kubernetes applications. We created a custom Helm chart from scratch that builds upon standard Kubernetes templates while implementing intelligent placement logic through native Kubernetes features.
The placement logic relies entirely on Kubernetes native features (node selectors, and priority classes) to ensure jobs land on the appropriate infrastructure. By properly configuring these parameters in our Helm chart, Kubernetes automatically makes optimal placement decisions based on cost, performance, and availability factors.
Here’s how easy it is for customers to specify their configuration:
name: ""
# Job configuration
backoffLimit: 3
ttlSecondsAfterFinished: 86400
# Training command and arguments
command:
- "python"
args:
- "/workspace/train.py"
# Model type
modelType: "default"
# Environment variables
env:
CUDA_VISIBLE_DEVICES: "all"
NCCL_DEBUG: "INFO"
# Persistent Volume Claims
dataPvcName: "training-data-pvc"
checkpointPvcName: "model-checkpoints-pvc"
nodeSelectors:
# Priority tiers for different node pools
hyperpod:
enabled: true
labels:
node-type: hyperpod
gpu-type: a100-80gb
eksDemand:
enabled: true
labels:
node-type: eks-on-demand
gpu-type: a100-40gb
eksSpot:
enabled: true
labels:
node-type: eks-spot
gpu-type: a100-40gb
priorityClasses:
# Priority class definitions based on job importance
critical:
value: 1000000
description: "Critical production training jobs that cannot be interrupted"
high:
value: 800000
description: "High priority training jobs for active development"
medium:
value: 600000
description: "Standard training jobs"
low:
value: 400000
description: "Experimental or research training jobs"
preemptible:
value: 200000
description: "Jobs that can be interrupted if necessary"
preemptionPolicy: PreemptLowerPriority
# Job configurations with different priorities and placement
jobTemplates:
production:
priorityClassName: critical
nodeSelector:
node-type: hyperpod
tolerations:
- key: "dedicated"
operator: "Equal"
value: "hyperpod"
effect: "NoSchedule"
resources:
limits:
nvidia.com/gpu: 8
requests:
nvidia.com/gpu: 8
memory: "64Gi"
cpu: "32"
development:
priorityClassName: high
nodeSelector:
node-type: eks-on-demand
resources:
limits:
nvidia.com/gpu: 4
requests:
nvidia.com/gpu: 4
memory: "32Gi"
cpu: "16"
research:
priorityClassName: medium
nodeSelector:
node-type: eks-spot
tolerations:
- key: "spot"
operator: "Equal"
value: "true"
effect: "NoSchedule"
resources:
limits:
nvidia.com/gpu: 2
requests:
nvidia.com/gpu: 2
memory: "16Gi"
cpu: "8"
This Helm chart implements several key features:
- Priority Classes: Defines a hierarchy of job priorities, ensuring that critical production workloads take precedence over experimental jobs
- Node Selectors: Strictly directs different types of workloads to the appropriate infrastructure (HyperPod for production, EKS on-demand for development, EKS spot for research)
- Resource Specifications: Tailors GPU, memory, and CPU requests based on workload type
- Tolerations: Ensures jobs can run on nodes with specific taints (like spot instances or dedicated HyperPod nodes)
When deployed, this configuration ensures:
- Production training jobs run on cost-effective, reliable HyperPod instances
- Development workloads use on-demand EKS instances when HyperPod is at capacity
- Research and experimental jobs leverage spot instances for maximum cost savings
- Critical jobs can preempt lower-priority workloads during resource constraints
The Results: 50% Cost Reduction and Faster Development Cycles
The hybrid solution delivered impressive results for our customer compared to their previous approach of using only on-demand GPU instances:
- 50% Reduction in GPU Costs: For the same $500K annual spend they were committing with their previous provider, our customer received twice the A100 GPU capacity through SageMaker HyperPod Flexible Training Plans. This effectively cut their per-GPU costs in half, while the hybrid architecture with EKS provides additional burst capacity when needed without increasing their baseline commitment.
- Significantly Improved Job Reliability: HyperPod’s built-in resilience features, including automatic node failure recovery and checkpoint resumption, provide additional protection for long-running training jobs, reducing the risk of losing progress due to infrastructure issues.
- Faster Time to Market: The ability to dynamically scale during peak periods has significantly accelerated model development cycles. Teams no longer face bottlenecks waiting for GPU resources during critical development phases. When urgent model iterations are needed, the system automatically provisions additional capacity through EKS, enabling parallel training runs and rapid experimentation that would have previously required sequential execution due to resource constraints.
- Simplified Operations: The end-to-end experience is streamlined through a single entry point. Data scientists submit jobs using familiar tools (kubectl, Jupyter notebooks, or CI/CD pipelines) with simple YAML configurations specifying their job type (production/development/research). The Kubernetes scheduler automatically places jobs on the appropriate infrastructure based on the configured node selectors and priorities.
Key Learnings and Best Practices
Through this implementation, we identified several best practices that are particularly relevant for organizations in specific scenarios:
This solution is ideal for:
- Companies developing large language models or foundation models that require frequent fine-tuning
- Organizations in financial services, healthcare, or e-commerce where AI model performance directly impacts revenue
- Teams running mixed workloads (training, fine-tuning, batch inference) with varying priority levels
- Businesses experiencing unpredictable or seasonal spikes in AI workload demand
Best practices we’ve identified:
- Start with Workload Analysis: Thoroughly understand your baseline and peak GPU requirements before committing to reserved capacity
- Design for Compatibility: Ensure your ML pipelines and workflows can operate identically in both environments
- Implement Smart Scheduling: Develop clear policies for workload routing that balance cost optimization with performance requirements
- Monitor Continuously: Implement comprehensive monitoring to identify optimization opportunities and prevent resource wastage
- Plan for Evolution: Create an architecture that can adapt as GPU availability, pricing, and AWS service capabilities evolve
Conclusion: Flexibility is the Future
In the rapidly evolving world of AI infrastructure, rigid solutions quickly become obsolete. Our hybrid approach demonstrates that organizations don’t need to choose between cost optimization and scalability; they can have both by intelligently combining AWS services.
This solution is now available as a reusable framework that can be customized for other organizations facing similar challenges. As an AWS Premier Tier Partner, Automat-it specializes in designing and implementing innovative solutions that maximize the value of AWS services while addressing real-world business challenges.
Ready to optimize your AI infrastructure?
Whether you’re just beginning your AI journey or looking to optimize an existing infrastructure, we can help you implement a similar hybrid approach tailored to your specific needs. Our team of certified AWS experts will:
- Analyze your current GPU utilization and costs
- Design a custom hybrid architecture based on SageMaker HyperPod and EKS
- Implement and deploy the solution tailored to your needs
Contact us today for a consultation to discover how Automat-it can help you achieve similar results.
